Overview
vLLM is an OpenAI-compatible provider for self-hosted inference. Bifrost delegates to the shared OpenAI provider implementation. Key characteristics:- OpenAI compatibility - Chat, text completions, embeddings, rerank, and streaming
- Self-hosted - Typically runs at
http://localhost:8000or your own server - Optional authentication - API key often omitted for local instances
- Responses API - Supported via chat completion fallback
Supported Operations
| Operation | Non-Streaming | Streaming | Endpoint |
|---|---|---|---|
| Chat Completions | ✅ | ✅ | /v1/chat/completions |
| Responses API | ✅ | ✅ | /v1/chat/completions |
| Text Completions | ✅ | ✅ | /v1/completions |
| Embeddings | ✅ | - | /v1/embeddings |
| Rerank | ✅ | - | /v1/rerank (fallback: /rerank) |
| List Models | ✅ | - | /v1/models |
| Image Generation | ❌ | ❌ | - |
| Speech (TTS) | ❌ | ❌ | - |
| Transcriptions (STT) | ✅ | ✅ | /v1/audio/transcriptions |
| Files | ❌ | ❌ | - |
| Batch | ❌ | ❌ | - |
Unsupported Operations (❌): Image Generation, Speech, Files, and Batch are not supported and return
UnsupportedOperationError.Setup & Configuration
Configure vLLM as a provider.- Web UI
- config.json
- API
- Go SDK
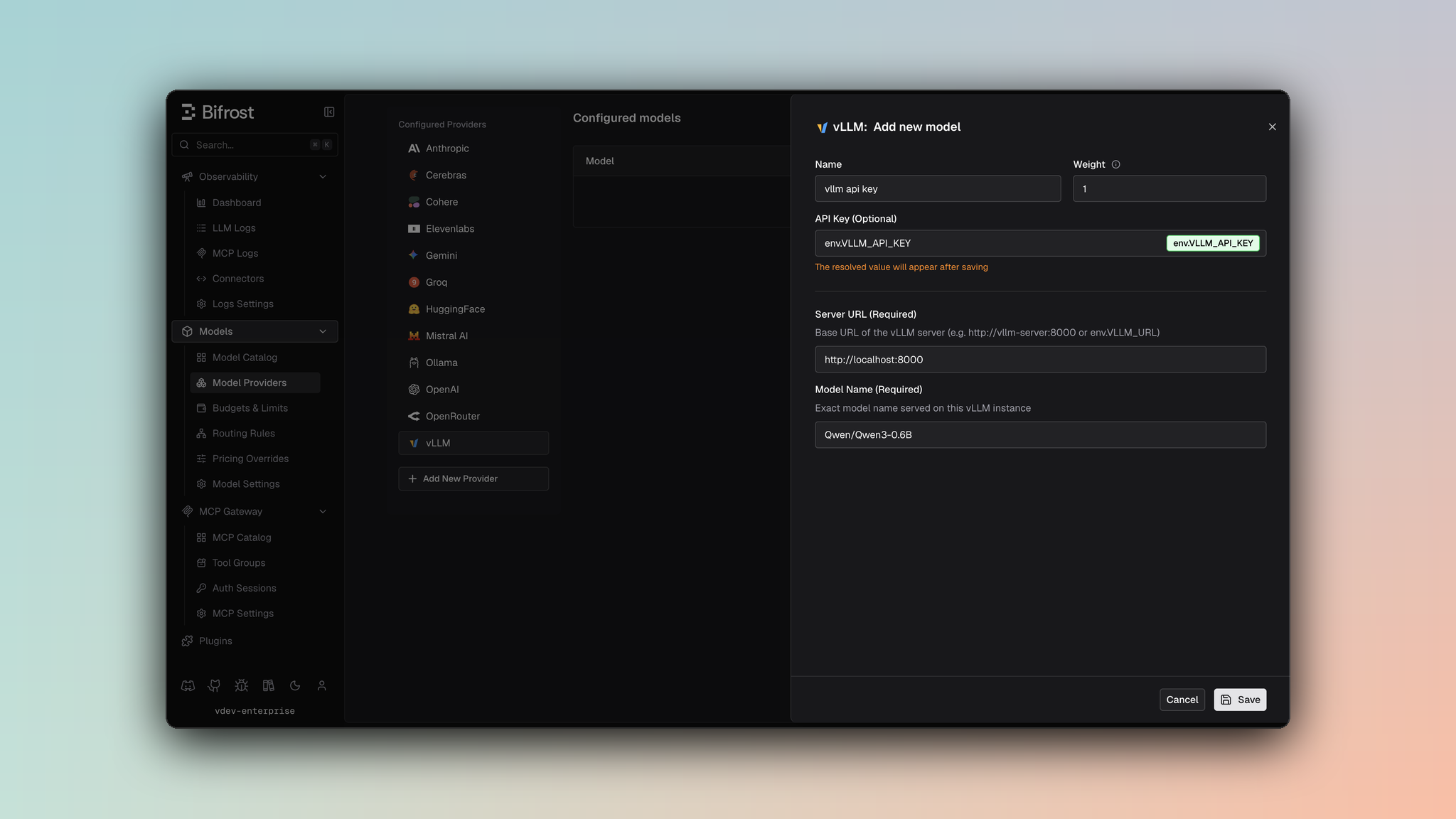
- Navigate to Models > Model Providers. Look for vLLM under Configured Providers. If it is missing, click on Add New Provider and select vLLM.
- Click Add New Model or edit an existing key.
- Set a name for your key.
- Leave API Key blank for local servers. If your endpoint requires auth, paste a bearer token directly or use an environment variable.
- Set vLLM URL to
http://localhost:8000and Model Name to the exact model loaded by the server. - Set Allowed Models to All Models (default) or the specific model allowlist you want this key to serve.
- Save the provider configuration.
Getting started
- Run a vLLM server (Docker or pip). Example with Docker:
- Verify the server:
- Use Bifrost with model prefix
vllm/<model_id>(e.g.vllm/meta-llama/Llama-3.2-1B-Instruct).
1. Chat Completions
vLLM supports standard OpenAI chat completion parameters. For full parameter reference, see OpenAI Chat Completions. Message types, tools, and streaming follow the same behavior.2. Responses API
Bifrost converts Responses API requests to Chat Completions and back:3. Text Completions
| Parameter | Mapping |
|---|---|
prompt | Sent as-is |
max_tokens | max_tokens |
temperature | temperature |
top_p | top_p |
stop | stop sequences |
4. Embeddings
vLLM supports/v1/embeddings. Use model IDs exposed by your vLLM server (e.g. BAAI/bge-m3).
5. List Models
Lists models from your vLLM instance via/v1/models. Available models depend on what is loaded on the server.
6. Rerank
vLLM supports reranking for pooling/cross-encoder reranker models. Bifrost sends requests to/v1/rerank and automatically falls back to /rerank when required by your vLLM deployment.
Your upstream vLLM server must be started with a rerank-capable model (pooling/cross-encoder task support).
Caveats
Per-key BaseURL Required
Per-key BaseURL Required
Severity: High
Behavior: vLLM resolves request routing from
vllm_key_config.url.
Impact: Requests fail without vllm_key_config.url, even if a provider-level network_config.base_url is present.Error responses with HTTP 200
Error responses with HTTP 200
Severity: Low
Behavior: vLLM may return HTTP 200 with an error payload (e.g.
Impact: Bifrost normalizes these into standard error responses so clients see consistent error handling.
Behavior: vLLM may return HTTP 200 with an error payload (e.g.
{"error": {"code": 404, "message": "..."}}) instead of 4xx/5xx.Impact: Bifrost normalizes these into standard error responses so clients see consistent error handling.