Looking for comprehensive provider routing documentation?For a detailed guide covering how adaptive load balancing works with governance routing, the two-level architecture (provider + key selection), Model Catalog integration, and example scenarios, see the Provider Routing Guide.This page focuses on the technical implementation and performance characteristics of adaptive load balancing.
Overview
Adaptive Load Balancing in Bifrost Enterprise automatically optimizes traffic distribution across providers and keys based on real-time performance metrics. The system operates at two levels - provider selection (direction) and key selection (route) - continuously monitoring error rates, latency, and throughput to dynamically adjust weights, ensuring optimal performance and reliability.Key Features
| Feature | Description |
|---|---|
| Dynamic Weight Adjustment | Automatically adjusts key weights based on performance metrics |
| Real-time Performance Monitoring | Tracks error rates, latency, and success rates per model-key combination |
| Cross-Node Synchronization | Gossip protocol ensures consistent weight information across all cluster nodes |
| Circuit Breaker Integration | Temporarily removes poorly performing keys from rotation |
| Fast Recovery | Momentum-based scoring helps routes recover quickly after transient failures |
Architecture
The load balancing system operates at two levels:- Direction-level (provider + model): Decides which provider to use for a given model
- Route-level (provider + model + key): Decides which API key to use within a provider
How Weight Calculation Works
Every 5 seconds, the system recalculates weights for all routes based on four factors:| Factor | Weight | Purpose |
|---|---|---|
| Error Penalty | 50% | Penalizes routes with high error rates |
| Latency Score | 20% | Penalizes routes with abnormally slow responses |
| Utilization Score | 5% | Prevents overloading high-performing routes |
| Momentum Bias | Additive | Rewards routes that are recovering well |
Key Capabilities
- Automatic Route Health Management: Routes automatically transition between 4 states (Healthy, Degraded, Failed, Recovering) based on error rates and latency. No manual intervention required when a route fails or recovers.
- Fair Traffic Distribution: The system prevents any single route from being overloaded while still favoring better performers. Low-weight routes always get minimum traffic to prove recovery.
- Real-time Dashboard: Provides visibility into weight distribution, performance metrics (error rates, latency), state transitions, and actual vs expected traffic per route.
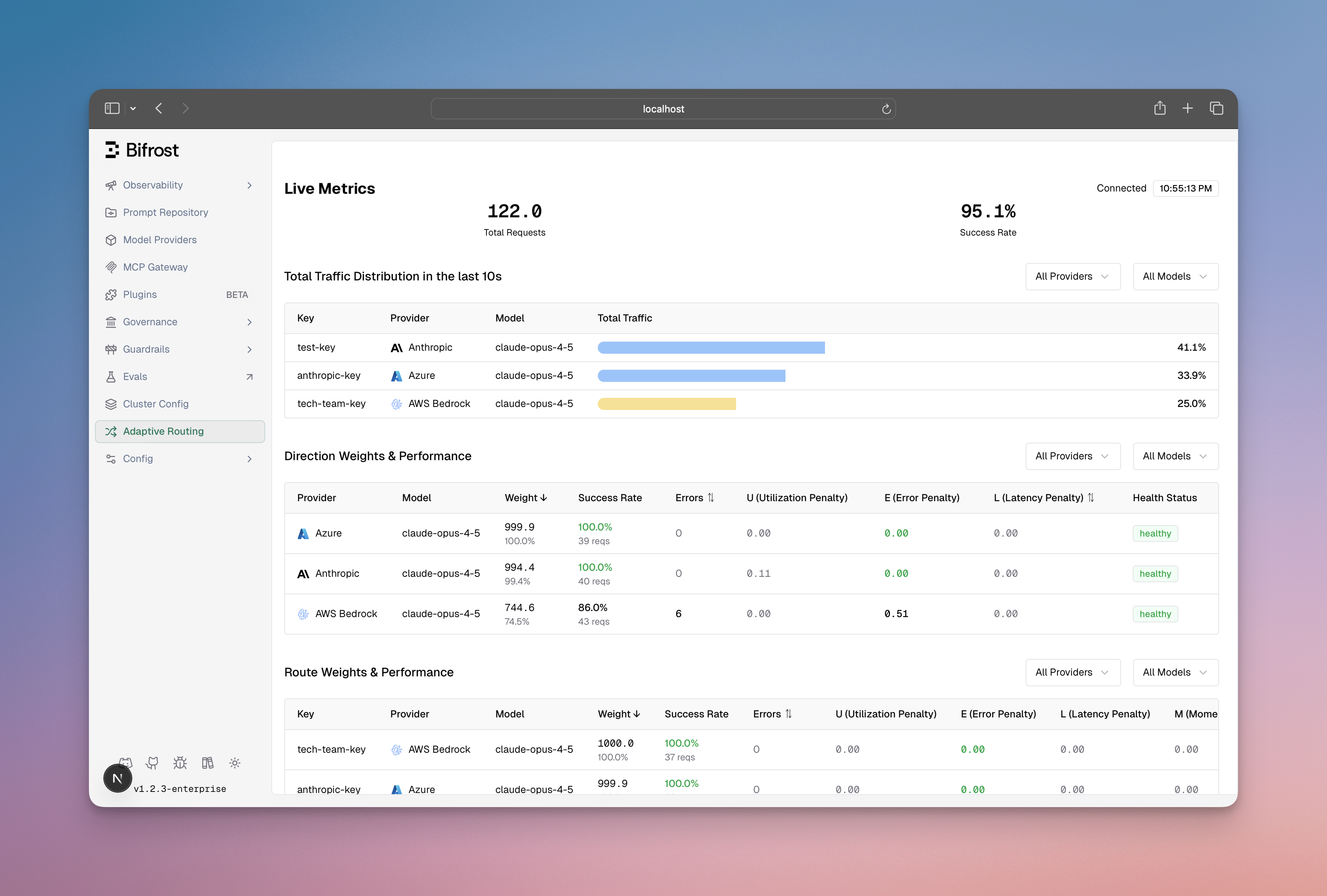
- Multi-Factor Scoring: Routes are scored using 4 components - Error Penalty (50% weight, time-decayed), Latency Score (token-aware via MV-TACOS algorithm), Utilization Score (fair-share balancing), and Momentum (accelerates recovery after failures).
- Smart Key Selection: Uses weighted random selection with jitter (5% band) and 25% exploration probability to probe potentially recovered routes, rather than always picking the best route.
- Performance Thresholds: Specific triggers drive state transitions -> 2% error rate triggers Degraded, >5% error rate or TPM hit triggers Failed, <2% error with 50%+ expected traffic triggers Healthy.
Next Steps
Enable Adaptive Load Balancing
Contact your Bifrost Enterprise representative to enable adaptive load balancing for your deployment