Overview
ElevenLabs is a specialized audio provider for text-to-speech and speech-to-text operations. Bifrost performs conversions including:- Model ID mapping - Uses provider model identifier directly
- Voice configuration - Maps voice settings (stability, similarity, boost, speed, style)
- Response format conversion - Speech format handling (MP3, Opus, PCM/WAV)
- Timestamp support - Character-level timing alignment for TTS
- Transcription with alignment - Word and character-level timing, diarization, and additional formats
- Pronunciation dictionaries - Support for custom pronunciation rules
- Voice quality parameters - Stability, similarity boost, and speaker boost controls
Supported Operations
| Operation | Non-Streaming | Streaming | Endpoint |
|---|---|---|---|
| Speech (TTS) | ✅ | ✅ | /v1/text-to-speech/{voice_id} |
| Transcriptions (STT) | ✅ | - | /v1/speech-to-text |
| List Models | ✅ | - | /v1/models |
| Chat Completions | ❌ | ❌ | - |
| Responses API | ❌ | ❌ | - |
| Text Completions | ❌ | ❌ | - |
| Embeddings | ❌ | ❌ | - |
| Image Generation | ❌ | ❌ | - |
Unsupported Operations (❌): Chat Completions, Responses API, Text Completions, and Embeddings are not supported by ElevenLabs (audio-focused provider). These return
UnsupportedOperationError.Note: ElevenLabs also supports a “Speech with Timestamps” endpoint at /v1/text-to-speech/{voice_id}/with-timestamps (non-streaming only) for enhanced timestamp information.Setup & Configuration
Configure ElevenLabs as a provider.- Web UI
- config.json
- API
- Go SDK
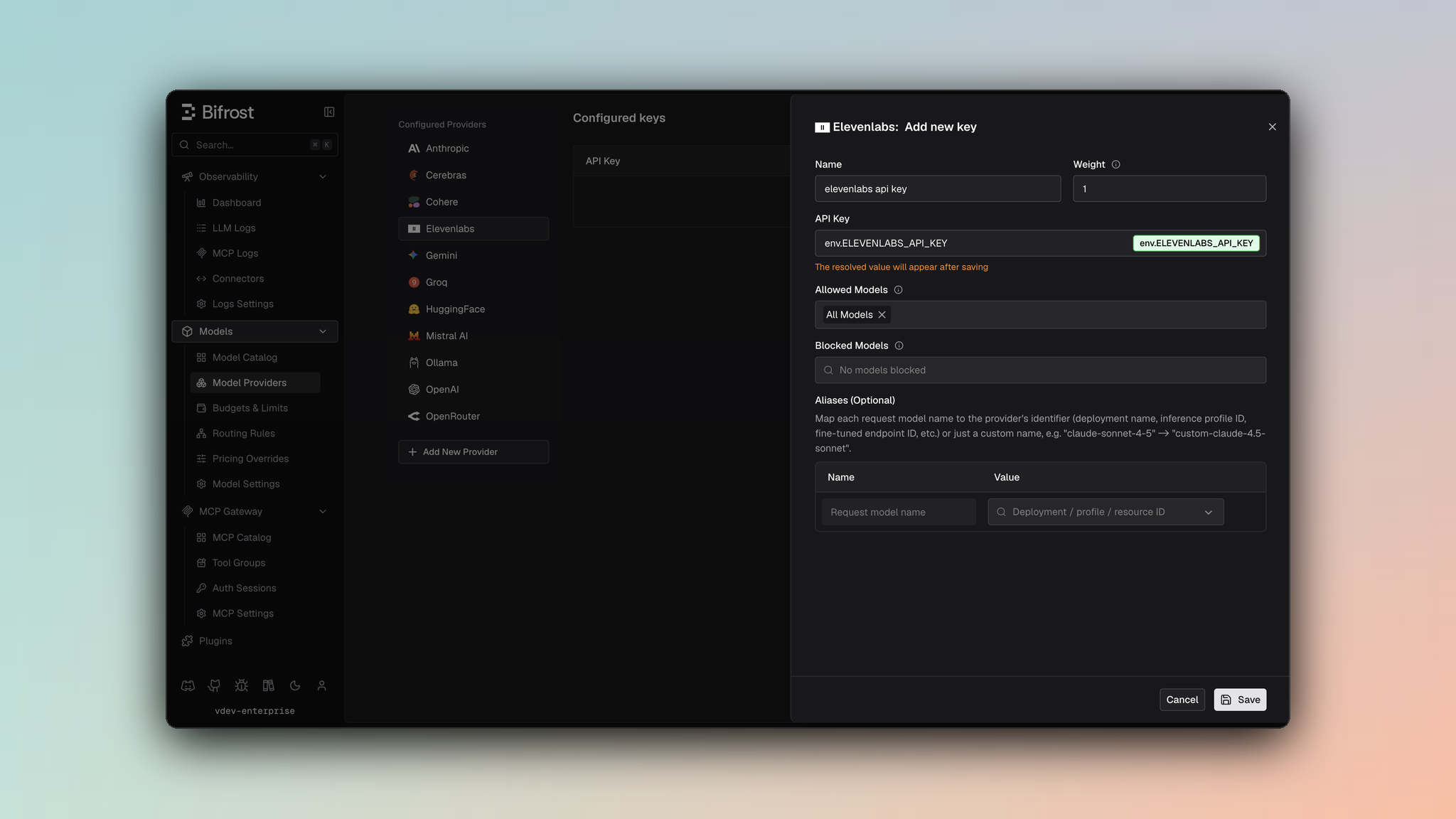
- Navigate to Models > Model Providers. Look for ElevenLabs under Configured Providers. If it is missing, click on Add New Provider and select ElevenLabs.
- Click Add Key or edit an existing key.
- Set a name for your key.
- Paste your API key directly or use an environment variable (for example,
env.ELEVENLABS_API_KEY). - Set Allowed Models to All Models (default) or the specific model allowlist you want this key to serve.
- Save the provider configuration.
model is the ElevenLabs voice ID unless you pass a provider-specific voice override in the request.
1. Speech (Text-to-Speech)
Request Parameters
Core Parameters
| Parameter | Mapping | Notes |
|---|---|---|
input.input | text | The text to convert to speech (required) |
model | model_id | Model identifier (e.g., "eleven_multilingual_v2") |
response_format | Query param output_format | Speech format (see Response Format) |
Voice Configuration
Voice settings are optional and controlled viaparams:
| Parameter | ElevenLabs Mapping | Default | Range |
|---|---|---|---|
speed | voice_settings.speed | 1.0 | 0.5-2.0 |
extra_params.stability | voice_settings.stability | 0.5 | 0-1.0 |
extra_params.similarity_boost | voice_settings.similarity_boost | 0.75 | 0-1.0 |
extra_params.use_speaker_boost | voice_settings.use_speaker_boost | true | boolean |
extra_params.style | voice_settings.style | 0 | 0-1.0 |
Advanced Parameters
Useextra_params for ElevenLabs-specific TTS features:
- Gateway
- Go SDK
Advanced TTS Parameters
| Parameter | Type | Description |
|---|---|---|
language_code | string | Language code (e.g., “en”, “es”) |
seed | integer | Reproducible output (0-4294967295) |
previous_text | string | Previous text context for consistency |
next_text | string | Next text context for consistency |
previous_request_ids | string[] | Previous request IDs for continuity |
next_request_ids | string[] | Next request IDs for continuity |
apply_text_normalization | string | Text normalization mode: "auto", "on", "off" |
apply_language_text_normalization | boolean | Apply language-specific text normalization |
Response Format
| Format | Output | Quality | Bitrate |
|---|---|---|---|
mp3 | MP3 | High | 128 kbps @ 44100 Hz |
opus | Opus | High | 128 kbps @ 48000 Hz |
wav / pcm | PCM WAV | Lossless | 16-bit @ 44100 Hz |
Defaults to MP3 format if not specified. Format is passed via query parameter
output_format.Timestamps Support
To get character-level timing alignment, enablewith_timestamps:
/v1/text-to-speech/{voice_id}/with-timestamps is used and the response includes:
audio_base64- Audio data as base64-encoded stringalignment.char_start_times_ms- Character start times in millisecondsalignment.char_end_times_ms- Character end times in millisecondsalignment.characters- Array of charactersnormalized_alignment- Same as alignment but for normalized text
Response Conversion
Non-Timestamp Response
Timestamp Response
Streaming
Streaming speech returns audio in chunks as they are generated:2. Transcription (Speech-to-Text)
Request Parameters
Input Source
Choose one of the following (mutually exclusive):| Parameter | Type | Description |
|---|---|---|
input.file | bytes | Audio file content (WAV, MP3, etc.) |
extra_params.cloud_storage_url | string | URL to cloud-hosted audio file |
Core Parameters
| Parameter | Mapping | Description |
|---|---|---|
model | model_id | Model identifier (required) |
params.language | language_code | Language code (ISO 639-1, e.g., “en”) |
Advanced Parameters
Useextra_params for transcription-specific features:
- Gateway
- Go SDK
Transcription Options
| Parameter | Type | Description |
|---|---|---|
tag_audio_events | boolean | Tag audio events (background noise, music, etc.) |
num_speakers | integer | Expected number of speakers (for diarization) |
timestamps_granularity | string | Timestamp level: "none", "word", "character" |
diarize | boolean | Identify different speakers |
diarization_threshold | float | Speaker diarization sensitivity (0.0-1.0) |
file_format | string | Input format: "pcm_s16le_16", "other" |
temperature | float | Transcription temperature (0.0-1.0) |
seed | integer | Reproducible transcription |
use_multi_channel | boolean | Process multi-channel audio separately |
webhook | boolean | Enable webhook for async processing |
webhook_id | string | Webhook endpoint ID |
webhook_metadata | object/string | Additional webhook metadata |
cloud_storage_url | string | URL to cloud-hosted audio (alternative to file) |
Additional Formats
Request multiple output formats simultaneously:segmented_json, docx, pdf, txt, html, srt
Response Conversion
Basic Transcription
With Diarization
Whendiarize: true, the response includes speaker identification:
With Timestamps
Character-level timing whentimestamps_granularity: "character":
With Additional Formats
Caveats
Voice ID Required
Voice ID Required
Severity: High
Behavior: Voice ID must be provided for TTS requests
Impact: Request fails without voice configuration
Code:
elevenlabs.go:198-208File or URL Required for Transcription
File or URL Required for Transcription
Severity: High
Behavior: Either
file or cloud_storage_url must be provided (not both)
Impact: Request fails with ambiguous input
Code: elevenlabs.go:471-478Audio Format Conversion
Audio Format Conversion
Severity: Low
Behavior: Response formats (MP3, Opus, WAV) mapped via format string
Impact: Format parameter passed as query string to endpoint
Code:
elevenlabs.go:712-715, utils.go:5-35Timestamps as Separate Endpoint
Timestamps as Separate Endpoint
Severity: Low
Behavior: Timestamp requests use
/with-timestamps endpoint variant
Impact: Switches endpoint based on with_timestamps flag
Code: elevenlabs.go:195-205Multipart Form Data for Transcription
Multipart Form Data for Transcription
Severity: Low
Behavior: Transcription uses multipart/form-data, not JSON
Impact: File and parameters sent as form fields
Code:
elevenlabs.go:480-6903. List Models
Request Parameters
| Parameter | Type | Description |
|---|---|---|
| (none) | - | No parameters required |