Get started
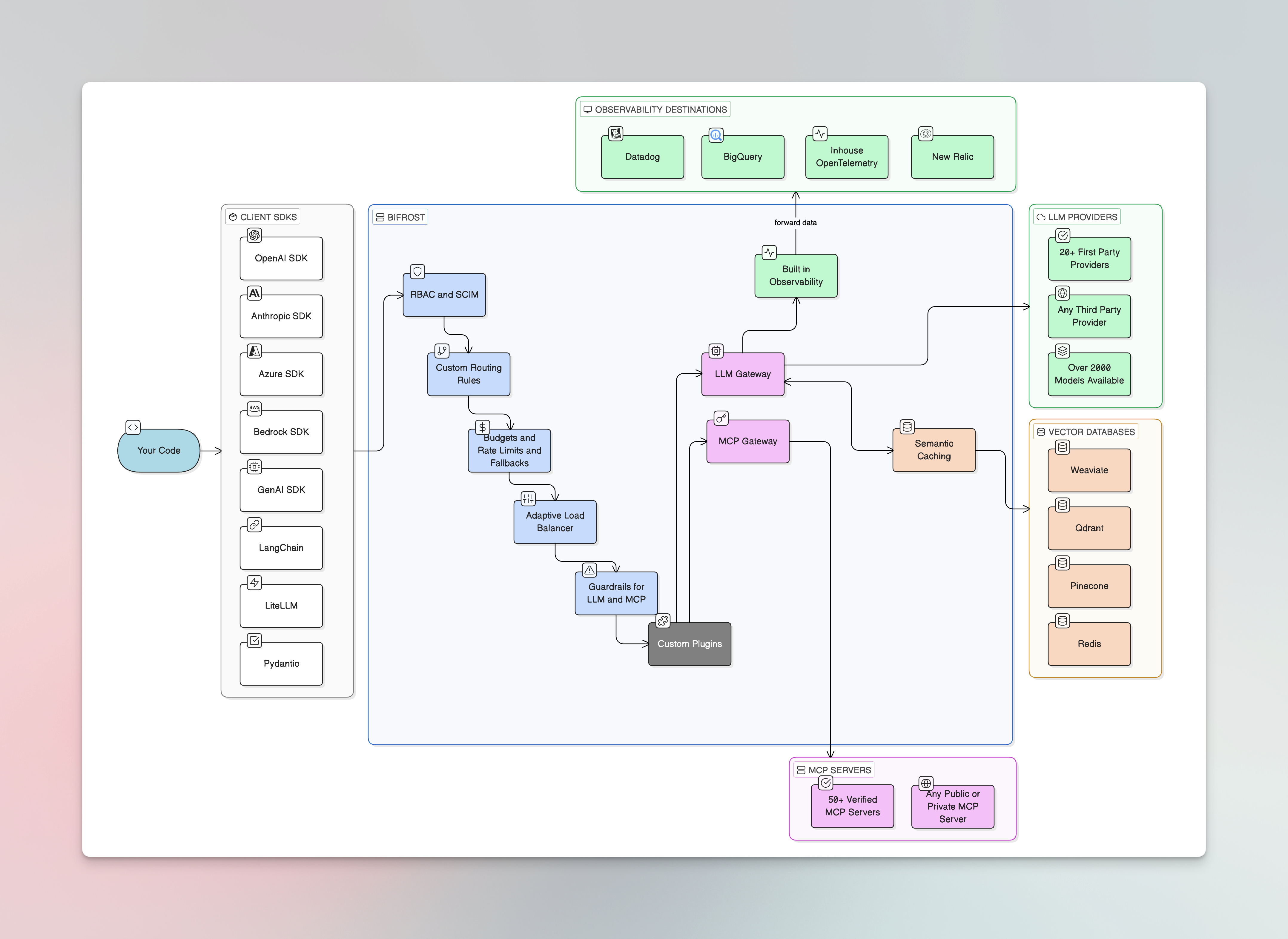
Gateway setup
Deploy the HTTP API gateway with a built-in web UI for visual configuration and real-time monitoring
Go SDK
Integrate directly into your Go application for maximum performance and control
Open source features
Drop-in Replacement
Replace existing AI SDK connections by changing just the base URL. Keep your code, gain fallbacks and governance.
Automatic Fallbacks
Seamless failover between providers and models. When your primary provider fails, Bifrost switches to backups automatically.
Load Balancing
Intelligent API key distribution with weighted load balancing, model-specific filtering, and automatic failover.
Virtual Keys
The primary governance entity. Control access permissions, budgets, rate limits, and routing per consumer.
Routing
Direct requests to specific models, providers, and keys. Implement weighted strategies and automatic fallbacks.
Budget & Rate Limits
Hierarchical cost control with budgets and rate limits at virtual key, team, and customer levels.
MCP Tool Filtering
Control which MCP tools are available per virtual key with strict allow-lists.
Semantic Caching
Intelligent response caching based on semantic similarity. Reduce costs and latency for similar queries.
Built-in Observability
Monitor every AI request in real-time. Track performance, debug issues, and analyze usage patterns.
Prometheus Metrics
Native Prometheus metrics via scraping or Push Gateway for monitoring and alerting.
OpenTelemetry
OTLP integration for distributed tracing with Grafana, New Relic, Honeycomb, and more.
Telemetry
Built-in Prometheus-based monitoring tracking HTTP-level and upstream provider metrics.
Custom Plugins
Extensible middleware architecture. Build Go or WASM plugins for custom logic.
Mocker Plugin
Mock AI provider responses for testing, development, and simulation.
MCP Gateway
Enable AI models to discover and execute external tools dynamically via the Model Context Protocol. Bifrost acts as both an MCP client and server, connecting to external tool servers and exposing tools to clients like Claude Desktop.Overview
Learn how Bifrost integrates MCP to transform static chat models into action-capable agents.
Tool Execution
Execute MCP tools with full control over approval, security validation, and conversation flow.
Agent Mode
Autonomous tool execution with configurable auto-approval for trusted operations.
Code Mode
Let AI write Python to orchestrate multiple tools - 50% less tokens, 40% lower latency.
MCP Authentication
Five auth types — None, Headers, OAuth 2.0, Per-User OAuth, Per-User Headers. Lazy auth for per-user.
Bifrost as an MCP Gateway
Expose Bifrost itself as an MCP server so Claude Desktop, Cursor, and other MCP clients can use your configured tools.
Tool Hosting
Register custom tools directly in your application and expose them via MCP.
Enterprise features
Advanced capabilities for teams running production AI systems at scale. Enterprise deployments include private networking, custom security controls, and governance features designed for enterprise-grade reliability.Guardrails
Content safety with AWS Bedrock Guardrails, Azure Content Safety, Google Model Armor, and Patronus AI for real-time protection.
Adaptive Load Balancing
Predictive scaling with real-time health monitoring, automatically optimizing traffic across providers.
Clustering
High-availability with automatic service discovery, gossip-based sync, and zero-downtime deployments.
Identity Providers (Okta, Entra)
OpenID Connect integration, user-level governance, team sync, and compliance frameworks.
Role-Based Access Control
Fine-grained permissions with custom roles controlling access across all Bifrost resources.
In-VPC Deployments
Deploy within your private cloud infrastructure with VPC isolation and enhanced security controls.
Audit Logs
Immutable audit trails for SOC 2, GDPR, HIPAA, and ISO 27001 compliance.
Datadog Connector
Native Datadog integration for APM traces, LLM Observability, and metrics.
Log Exports
Automated export of request logs and telemetry to storage systems and data lakes.
SDK integrations
Use Bifrost as a drop-in replacement for popular AI SDKs with zero code changes - just update the base URL.OpenAI SDK
Drop-in replacement for the OpenAI Python and Node.js SDKs.
Anthropic SDK
Drop-in replacement for the Anthropic Python and TypeScript SDKs.
Bedrock SDK
Native AWS Bedrock SDK integration with full model support.
GenAI SDK
Drop-in replacement for the Google GenAI SDK.
LiteLLM
Compatibility with LiteLLM proxy and SDK for unified model access.
LangChain
Integration with the LangChain framework for building AI applications.
PydanticAI
Integration with PydanticAI for type-safe AI agent development.
Supported providers
Bifrost supports 20+ AI providers through a single unified API. Configure multiple providers and Bifrost handles routing, failover, and load balancing automatically. See the full provider support matrix for detailed capability comparisons.OpenAI
GPT-4o, o1, GPT-4, and more with full feature support.
Anthropic
Claude 4, Claude 3.5, and Claude 3 model family.
AWS Bedrock
Multi-model access with native AWS authentication.
Google Vertex AI
Gemini and PaLM models with OAuth2 authentication.
Azure OpenAI
OpenAI models via Azure with deployment management.
Google Gemini
Gemini models with vision, audio, and embeddings.
Groq
Ultra-fast inference with LPU hardware acceleration.
Mistral
Mistral and Mixtral models with tool support.
Cohere
Command models with chat, embeddings, and reasoning.
Cerebras
High-speed inference with full streaming support.
DeepSeek
OpenAI-compatible chat, reasoning, tools, and FIM completions.
Ollama
Local inference with OpenAI-compatible format.
Hugging Face
Inference API with chat, vision, TTS, and STT.
OpenRouter
Route to multiple providers with reasoning support.
Perplexity
Web search integration with reasoning support.
ElevenLabs
Text-to-speech and speech-to-text models.
Nebius
OpenAI-compatible with streaming and embeddings.
xAI
Grok models with vision and reasoning support.
Parasail
Chat and streaming with tool calling support.
Replicate
Prediction-based architecture with async modes.
SGL
SGLang runtime with streaming and embeddings.
vLLM
Self-hosted OpenAI-compatible inference with chat, embeddings, and STT.