Overview
Guardrails in Bifrost provide enterprise-grade content safety, security validation, and policy enforcement for LLM requests and responses. The system validates inputs and outputs in real-time against your specified policies, ensuring responsible AI deployment with protection against harmful content, prompt injection, PII leakage, credential leakage, and policy violations.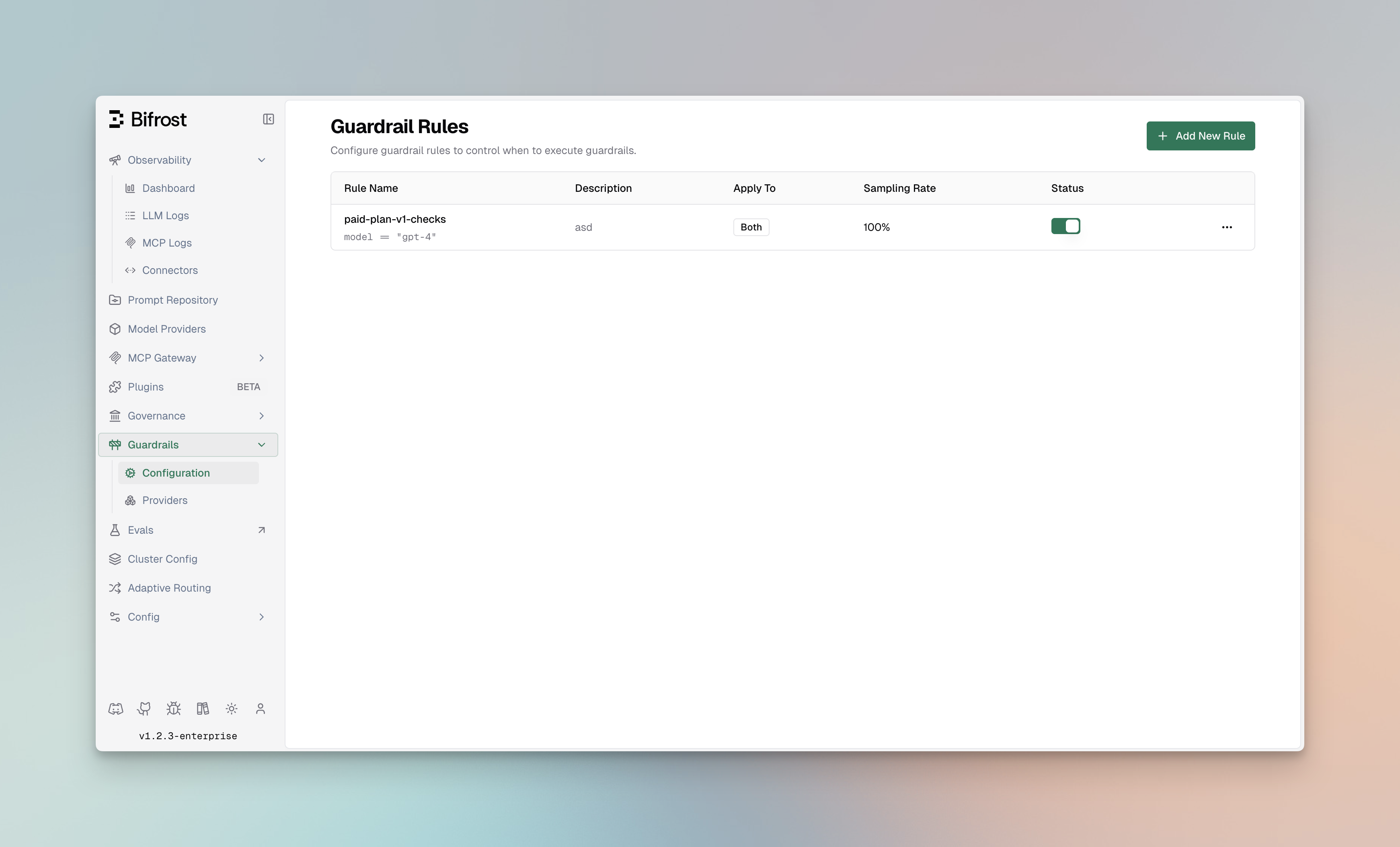
Supported Providers
Secrets Detection
Built-in Gitleaks-backed detection for leaked API keys, tokens, private keys, and credentials.
Custom Regex
In-process regex guardrails, including the built-in PII Detection template.
Microsoft Presidio
Presidio Analyzer based PII detection, blocking, and redaction.
Azure AI Language PII
Azure Language PII entity recognition with configurable categories and redaction.
AWS Bedrock Guardrails
Enterprise content filtering, PII detection, and prompt attack prevention.
Azure Content Safety
Multi-modal content moderation with severity-based filtering.

Google Model Armor
Google Cloud policy enforcement for prompt injection, content safety, malicious URLs, and Sensitive Data Protection.

CrowdStrike AIDR
Inline AI threat detection, policy enforcement, redaction, and AIDR audit visibility.
Gray Swan Cygnal
AI safety monitoring with natural language rule definitions.
Patronus AI
LLM security, hallucination detection, and safety evaluation.
Lakera Guard
Threat detection for LLM conversations, including prompt injection and sensitive data exposure.
Repello Argus
Asset-defined AI security policies for prompt injection, sensitive data, unsafe content, and policy violations.
Core Concepts
Bifrost Guardrails are built around two core concepts that work together to provide flexible and powerful content protection:
How They Work Together:
- Profiles define how content is evaluated using native Bifrost checks or external provider capabilities
- Rules define when and what content gets evaluated using CEL expressions
- A single rule can use multiple profiles for layered protection
- Profiles can be reused across different rules for consistency
Key Features
Redaction
Supported providers can redact detected text instead of only detecting or blocking it. Bifrost supports three redaction modes:- Runtime (
runtime) redacts the live request or response and stores redacted values in logs. - Logs only (
logs_only) leaves runtime content raw but redacts Bifrost logs and trace-export connector content. - Runtime + reversible logs (
runtime_reversible) redacts runtime content and logs with reversible placeholders.
Navigating Guardrails in the UI
Access Guardrails from the Bifrost dashboard:Architecture
The following diagram illustrates how Rules and Profiles work together to validate LLM requests: Flow Description:- Incoming Request - LLM request arrives at Bifrost
- Input Validation - Applicable rules evaluate the input using linked profiles
- LLM Processing - If input passes, request is forwarded to the LLM provider
- Output Validation - Response is evaluated by output rules using linked profiles
- Response - Validated response is returned (or blocked/modified based on violations)
Streaming Output Guardrails
Streaming delivery depends on what the matched output guardrails can do:- Detect-only and logs-only rules observe the stream without delaying client delivery.
- Runtime redaction checks buffered text segments and releases the resulting safe text as the response is generated.
- If any matched rule can block, Bifrost holds the complete stream until generation and guardrail evaluation finish. If
stream_replay_event_interval_msis positive, an allowed stream is replayed with that delay between buffered events; otherwise, it is delivered immediately. A blocked stream returns the guardrail intervention instead.
25 milliseconds when pacing is enabled, while 0 sends all buffered events immediately. If multiple matched block-capable rules configure different intervals, Bifrost uses the largest value. This behavior applies to streaming Chat Completions, Text Completions, and Responses API requests.
Input guardrails still check the request before Bifrost sends it to the LLM provider.
Gray Swan is a tool-call-specific exception. Text-only streams are delivered directly to the client and are not sent to Cygnal. See Gray Swan Cygnal for the full behavior.
If the same rule also uses another output guardrail profile, Bifrost waits for that profile to check the completed response. Gray Swan’s text-only behavior only skips the Gray Swan call; it does not bypass the other profile.
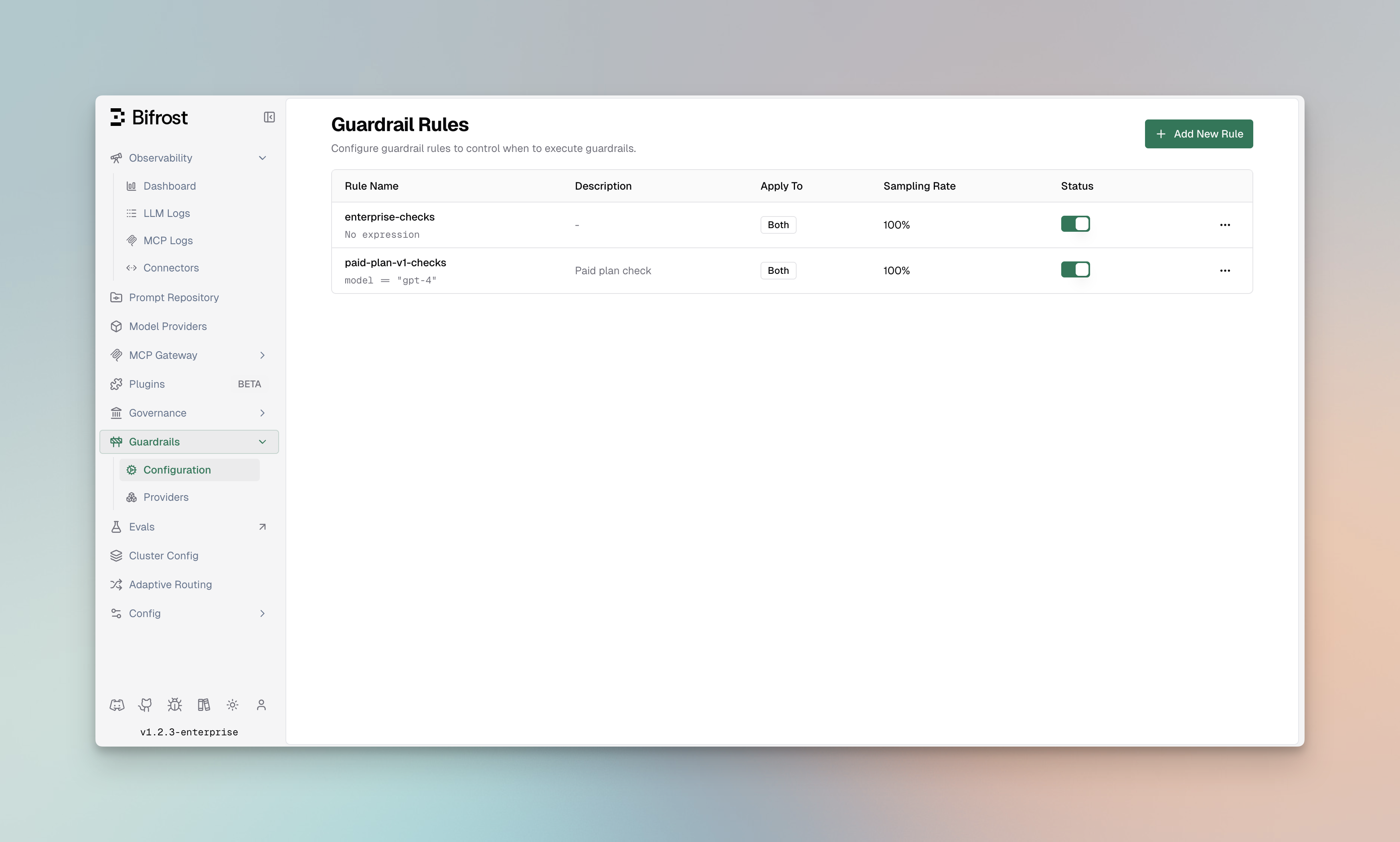
Guardrail Rules
Guardrail Rules are custom policies that define when and how content validation occurs. Rules use CEL (Common Expression Language) expressions to evaluate requests and can be linked to one or more profiles for execution.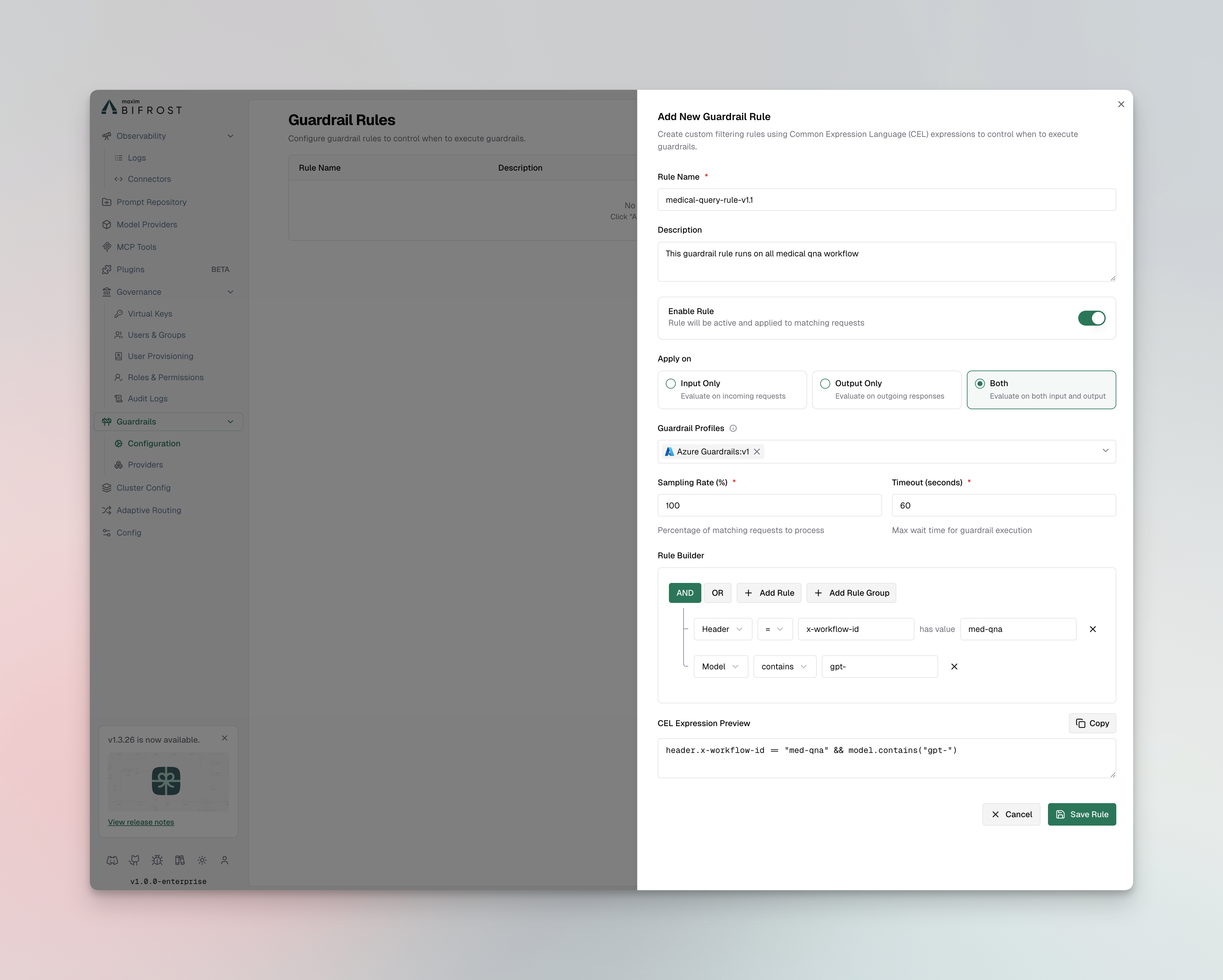
Rule Properties
Creating Rules
- Web UI
- API
- config.json
- Helm
- Navigate to Rules
- Go to Guardrails > Configuration
- Click Add Rule
- Configure Rule Settings
- Name: Enter a descriptive name (e.g., “Block PII in Prompts”)
- Description: Explain the rule’s purpose
- Enabled: Toggle to activate the rule
- Apply To: Select when to apply the rule
input- Validate incoming prompts onlyoutput- Validate LLM responses onlyboth- Validate both inputs and outputs
- CEL Expression: Define the validation logic
- Sampling Rate: Set percentage of requests to evaluate (default: 100%)
- Timeout: Set maximum execution time in seconds (default: 60)
-
Link Profiles
- Select one or more profiles to use for evaluation
- Bifrost evaluates linked profiles in their configured order and stops that rule when a profile intervenes or fails
-
Save and Test
- Click Save Rule
- Use the Test button to validate with sample content
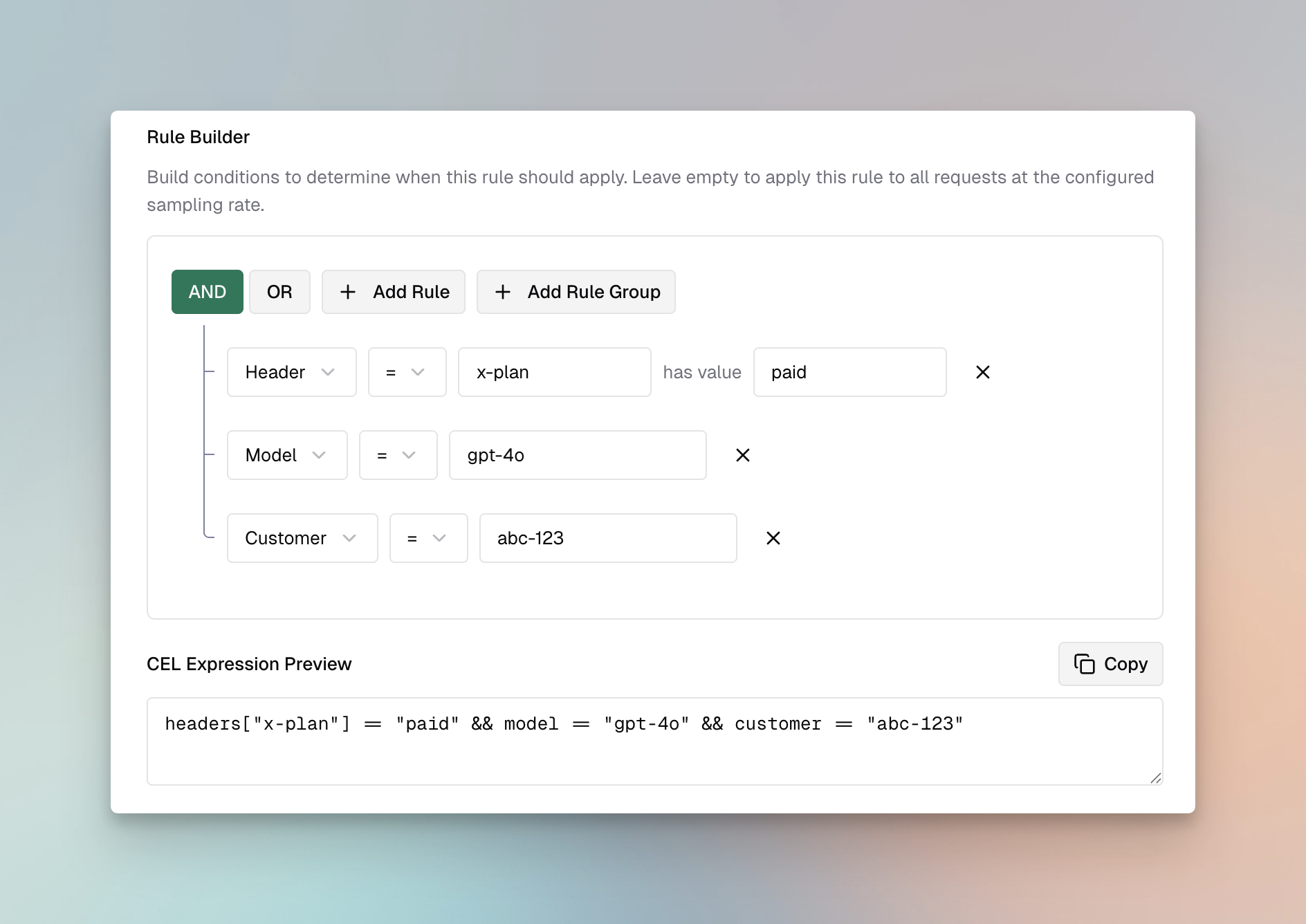
CEL Expression Examples
CEL (Common Expression Language) provides a powerful way to define rule conditions. Here are common patterns: Always Apply Rule:Linking Rules to Profiles
Rules can be linked to multiple profiles for comprehensive validation:- Link credential-leakage rules to Secrets Detection
- Link PII detection rules to profiles with PII capabilities (Custom Regex PII template, Presidio, Azure AI Language PII, Bedrock, Patronus)
- Link content filtering rules to profiles with content safety features (Azure, Bedrock, Gray Swan)
- Use Gray Swan for custom natural language rules when you need flexible, readable policies
- Use multiple profiles for defense-in-depth (e.g., Bedrock + Patronus for PII, Azure + Gray Swan for content)
- Set appropriate timeouts when using multiple profiles
Managing Profiles
Profiles are reusable configurations for guardrail providers. External providers include credentials, endpoints, and detection thresholds. Bifrost-native providers such as Custom Regex and Secrets Detection run locally and do not require external service credentials.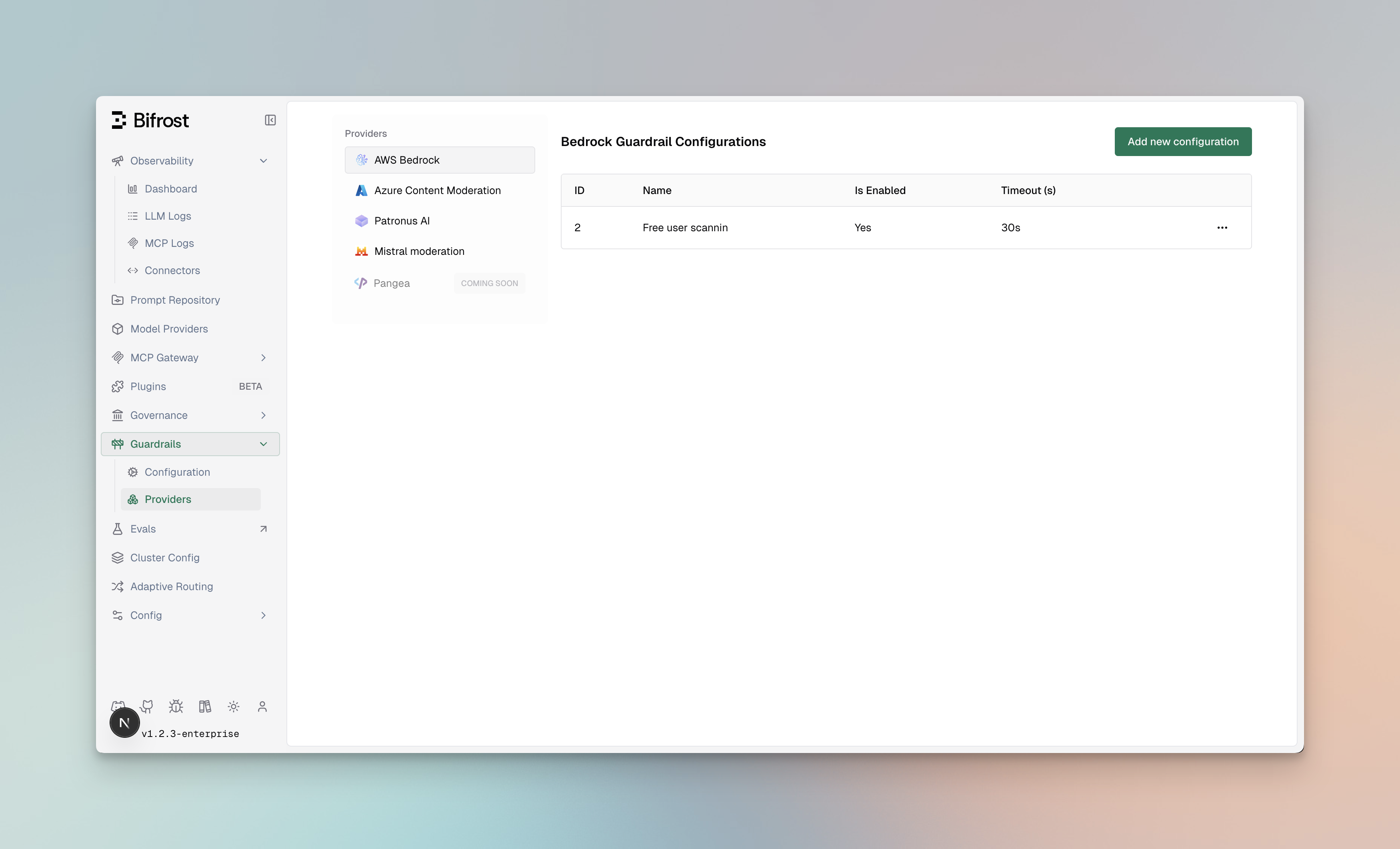
Profile Properties
Creating Profiles
- Web UI
- API
- config.json
- Helm
- Navigate to Providers
- Go to Guardrails > Providers
- Click Add Profile
-
Select Provider Type
- Choose a supported native or external provider, including Lakera Guard
-
Configure Provider Settings
- Enter credentials and endpoint information for external providers, or local settings for native providers
- Configure detection thresholds and actions
- See provider-specific setup sections above for detailed configuration
-
Save Profile
- Click Save Profile
- The profile is now available for linking to rules
Provider Capabilities
Third-party guardrail providers offer different capabilities. Bifrost-native providers are documented separately: Secrets Detection covers credential leakage, Custom Regex covers deterministic pattern checks, and Guardrail Redaction covers Bifrost-managed redaction modes.CrowdStrike AIDR capabilities depend on the AIDR policy and detectors configured in CrowdStrike. Bifrost sends the request to AIDR, then enforces the returned
blocked or transformed decision.Best Practices
Profile Organization:- Create separate profiles for different use cases (PII, content filtering, etc.)
- Use descriptive policy names that indicate the profile’s purpose
- Keep credentials secure using environment variables
- Enable only the profiles you need to minimize latency
- Use sampling rates on rules for high-traffic endpoints
- Set appropriate timeouts to prevent slow requests
- Store API keys and credentials in environment variables or secrets managers
- Regularly rotate credentials
- Use least-privilege IAM roles for AWS Bedrock
- Use least-privilege Google IAM roles for Google Model Armor, such as
roles/modelarmor.useror a higher Model Armor role