Overview
OpenAI is the baseline schema for Bifrost. When using OpenAI directly, parameters are passed through with minimal conversion - mostly validation and filtering of OpenAI-specific features.
Supported Operations
| Operation | Non-Streaming | Streaming | Endpoint |
|---|
| Chat Completions | ✅ | ✅ | /v1/chat/completions |
| Responses API | ✅ | ✅ | /v1/responses |
| Text Completions | ✅ | ✅ | /v1/completions |
| Embeddings | ✅ | - | /v1/embeddings |
| Speech (TTS) | ✅ | ✅ | /v1/audio/speech |
| Transcriptions (STT) | ✅ | ✅ | /v1/audio/transcriptions |
| Image Generation | ✅ | ✅ | /v1/images/generations |
| Image Edit | ✅ | ✅ | /v1/images/edits |
| Image Variation | ✅ | - | /v1/images/variations |
| Files | ✅ | - | /v1/files |
| Batch | ✅ | - | /v1/batches |
| Video Generation | ✅ | - | /v1/videos |
| Context Compaction | ✅ | - | /v1/responses/compact |
| List Models | ✅ | - | /v1/models |
Setup & Configuration
Configure OpenAI as a provider.
Web UI
config.json
API
Go SDK
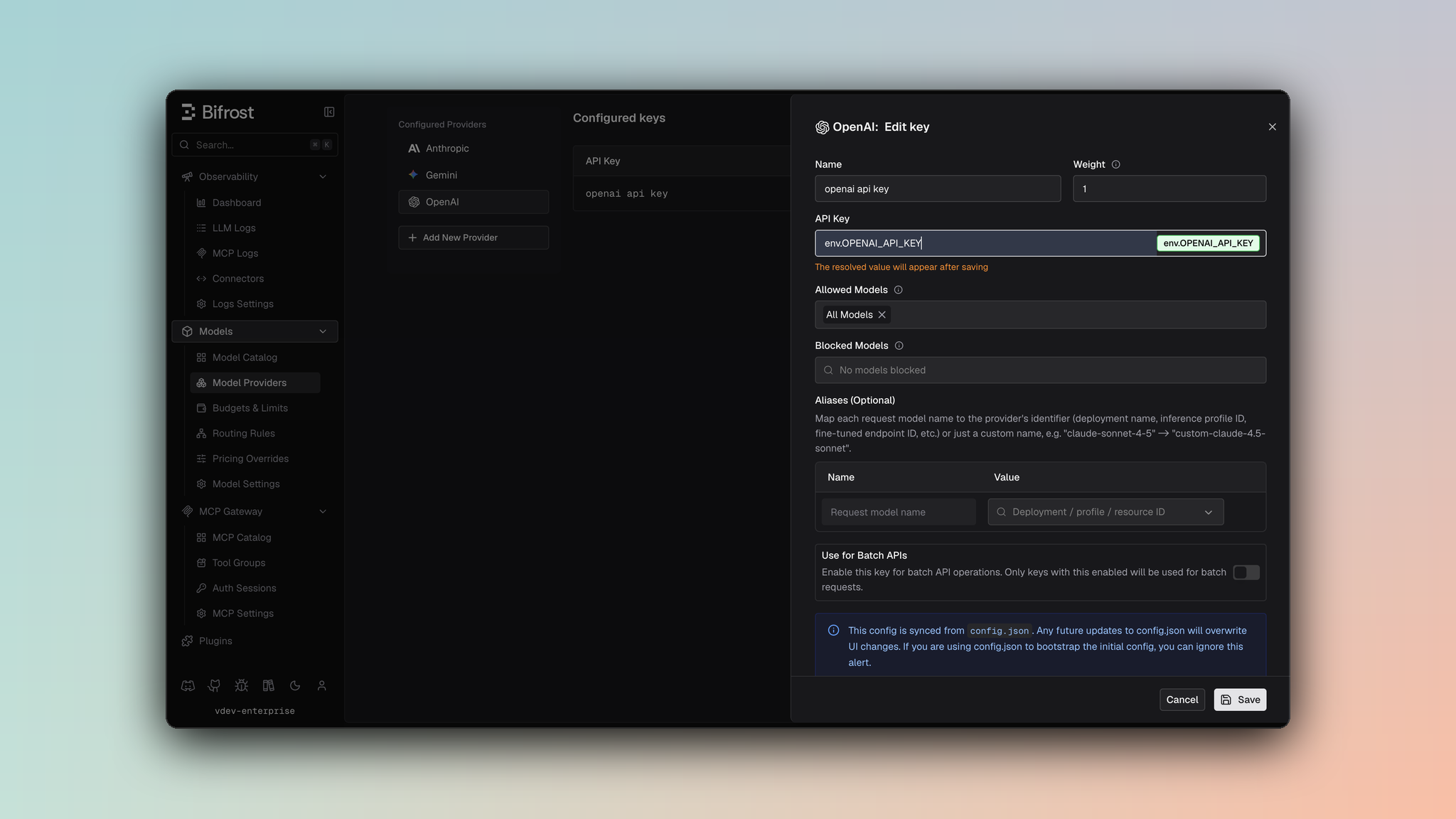
- Navigate to Models > Model Providers. Look for OpenAI under Configured Providers. If it is missing, click on Add New Provider and select OpenAI.
- Click Add Key or edit an existing key.
- Set a name for your key.
- Paste your API key directly or use an environment variable (for example,
env.OPENAI_API_KEY).
- Set Allowed Models to All Models (default) or the specific model allowlist you want this key to serve.
- Save the provider configuration.
{
"providers": {
"openai": {
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": [
"*"
],
"weight": 1.0
}
],
"openai_config": {
"disable_store": false
}
}
}
}
Refer to the API documentation for Provider Keys Management. case schemas.OpenAI:
return []schemas.Key{{
Name: "openai-key-1",
Value: *schemas.NewEnvVar("env.OPENAI_API_KEY"),
Models: []string{"*"},
Weight: 1.0,
}}, nil
network_config for timeouts, retries, proxy/TLS settings, and openai_config.disable_store to force store=false on outgoing OpenAI requests.
1. Chat Completions
Request Parameters
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier |
messages | array | ✅ | ChatMessage array with roles (docs) |
temperature | float | ❌ | Sampling temperature (0-2) |
top_p | float | ❌ | Nucleus sampling parameter |
stop | string/array | ❌ | Stop sequences |
max_completion_tokens | int | ❌ | Min 16, max output tokens |
frequency_penalty | float | ❌ | Frequency penalty (-2 to 2) |
presence_penalty | float | ❌ | Presence penalty (-2 to 2) |
logit_bias | object | ❌ | Token logit adjustments |
logprobs | bool | ❌ | Include log probabilities |
top_logprobs | int | ❌ | Number of log probabilities per token |
seed | int | ❌ | Reproducibility seed |
response_format | object | ❌ | Output format (docs) |
tools | array | ❌ | Tool objects (docs) |
tool_choice | string/object | ❌ | "auto", "none", "required", or specific tool |
parallel_tool_calls | bool | ❌ | Allow multiple simultaneous tool calls |
stream_options | object | ❌ | Streaming options (docs) |
reasoning | object | ❌ | Reasoning parameters (Bifrost docs, OpenAI docs) |
user | string | ❌ | Truncated to 64 chars |
metadata | object | ❌ | Custom metadata |
store | bool | ❌ | Filtered for non-OpenAI routing |
service_tier | string | ❌ | Filtered for non-OpenAI routing |
prompt_cache_key | string | ❌ | Filtered for non-OpenAI routing |
prediction | object | ❌ | Predicted output for acceleration |
audio | object | ❌ | Audio output config |
modalities | array | ❌ | Response modalities (text, audio) |
- Reasoning: OpenAI supports
reasoning.effort (minimal, low, medium, high) and reasoning.max_tokens - both passed through directly. When routing to other providers, "minimal" effort is converted to "low" for compatibility. See Bifrost reasoning docs.
- Messages: All message roles are supported:
system, user, assistant, tool, developer (treated as system). Content types: text, images via URL (image_url), audio input (input_audio). Tool messages include a tool_call_id.
- Tools: Standard OpenAI tool format with strict mode support. Tool choice:
"auto", "none", "required", or specific tool by name.
- Responses: Passed through in standard OpenAI format. Finish reasons:
stop, length, tool_calls, content_filter. Usage includes token counts and optionally cached/reasoning token details.
- Streaming: Server-Sent Events format with
delta.content, delta.tool_calls, finish_reason, and usage (final chunk only, automatically included by Bifrost). stream_options: { include_usage: true } is set by default for all streaming calls.
- Cache Control:
cache_control fields are stripped from messages, their content blocks, and tools before sending.
- Token Enforcement:
max_completion_tokens is enforced to have a minimum of 16. Values below 16 are automatically set to 16.
- Special handling:
user field is truncated to 64 characters; prompt_cache_key, store, service_tier are filtered when routing to non-OpenAI providers
2. Responses API
The Responses API is OpenAI’s structured output API.
Request Parameters
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier |
input | string/array | ✅ | Text or ContentBlock array (docs) |
max_output_tokens | int | ✅ | Maximum output length |
background | bool | ❌ | Run request in background mode |
conversation | string | ❌ | Conversation ID for continuing a conversation |
include | array | ❌ | Array of fields to include in response (e.g., "web_search_call.action.sources") |
instructions | string | ❌ | System instructions |
max_tool_calls | int | ❌ | Maximum number of tool calls |
metadata | object | ❌ | Custom metadata |
parallel_tool_calls | bool | ❌ | Allow multiple simultaneous tool calls |
previous_response_id | string | ❌ | ID of previous response to continue from |
prompt_cache_key | string | ❌ | Prompt caching key |
reasoning | object | ❌ | ResponsesParametersReasoning configuration (Bifrost docs) |
safety_identifier | string | ❌ | Safety identifier for content filtering |
service_tier | string | ❌ | Service tier for the request |
stream_options | object | ❌ | ResponsesStreamOptions configuration |
store | bool | ❌ | Store the response for later retrieval |
temperature | float | ❌ | Sampling temperature |
text | object | ❌ | ResponsesTextConfig for output formatting |
top_logprobs | int | ❌ | Number of log probabilities to return per token |
top_p | float | ❌ | Nucleus sampling parameter |
tool_choice | string/object | ❌ | ResponsesToolChoice strategy |
tools | array | ❌ | ResponsesTool objects (docs) |
truncation | string | ❌ | Truncation strategy (auto or off) |
user | string | ❌ | Truncated to 64 chars |
Special Message Handling (gpt-oss vs other models):
OpenAI models handle reasoning differently depending on the model family:
- Non-gpt-oss models (GPT-4o, o1, etc.): Send reasoning as summaries. Reasoning-only messages (with no summary and only content blocks) are filtered out since these models don’t support reasoning content blocks in the request format.
- gpt-oss models: Send reasoning as content blocks. Reasoning summaries in the request are converted to content blocks since gpt-oss expects reasoning as structured blocks, not summaries.
This conversion ensures compatibility across different model architectures for the structured Responses API. See Bifrost reasoning docs for detailed reasoning handling.
Token & Parameter Enforcement:
max_output_tokens is enforced to have a minimum of 16. Values below 16 are automatically set to 16.reasoning.max_tokens field is automatically removed from JSON output (OpenAI Responses API doesn’t accept it).
Other conversions:
- Action types
zoom and region are converted to screenshot
cache_control fields are stripped from messages and tools- Unsupported tool types are silently filtered (only these are supported:
function, file_search, computer_use_preview, web_search, mcp, code_interpreter, image_generation, local_shell, custom, web_search_preview)
Response: Includes id, status (completed, incomplete, pending, error), output array with message content, and token usage.
Streaming: Server-Sent Events with types: response.created, response.in_progress, response.output_item.added, response.content_part.added, response.output_text.delta, response.function_call_arguments.delta, response.completed, response.incomplete. stream_options: { include_usage: true } is set by default for all streaming calls.
3. Text Completions (Legacy)
Text Completions is a legacy API. Use Chat Completions for new implementations.
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier |
prompt | string/array | ✅ | Completion prompt(s) |
max_tokens | int | ❌ | Maximum output tokens |
temperature | float | ❌ | Sampling temperature |
top_p | float | ❌ | Nucleus sampling |
stop | string/array | ❌ | Stop sequences |
user | string | ❌ | Truncated to 64 chars |
- Array prompts generate multiple completions. Finish reasons:
stop or length. Streaming uses SSE format. stream_options: { include_usage: true } is set by default for streaming calls.
user field is truncated to 64 characters or set to nil if it exceeds the limit.
4. Embeddings
Request Parameters
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier |
input | string/array | ✅ | Text(s) to embed (docs) |
encoding_format | string | ❌ | float or base64 |
dimensions | int | ❌ | Output embedding dimensions |
user | string | ❌ | NOT truncated (unlike chat/text) |
- No streaming support. Returns
embedding array with usage counts.
5. Speech (Text-to-Speech)
Request Parameters
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | tts-1 or tts-1-hd |
input | string | ✅ | Text to convert to speech |
voice | string | ✅ | alloy, echo, fable, onyx, nova, shimmer |
response_format | string | ❌ | mp3, opus, aac, flac, wav, pcm |
speed | float | ❌ | 0.25 to 4.0 (default 1.0) |
- Returns raw binary audio. Streaming supported in SSE format (base64 chunks), but not all models support streaming.
stream_options: { include_usage: true } is set by default for streaming calls.
6. Transcriptions (Speech-to-Text)
Requests use multipart/form-data, not JSON.
| Parameter | Type | Required | Notes |
|---|
file | binary | ✅ | Audio file (multipart form-data) |
model | string | ✅ | whisper-1 |
language | string | ❌ | ISO-639-1 language code |
prompt | string | ❌ | Optional prompt for context |
temperature | float | ❌ | Sampling temperature |
response_format | string | ❌ | json, text, srt, vtt, verbose_json |
- Supported audio formats: mp3, mp4, mpeg, mpga, m4a, wav, webm
- Response: Includes
text, task, language, duration, and optionally word-level timing. Streaming supported in SSE format. stream_options: { include_usage: true } is set by default for streaming calls.
7. Image Generation
Request Parameters
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier (e.g., dall-e-3) |
prompt | string | ✅ | Text description of the image to generate |
n | int | ❌ | Number of images to generate (1-10) |
size | string | ❌ | Image size: "256x256", "512x512", "1024x1024", "1792x1024", "1024x1792", "1536x1024", "1024x1536", "auto" |
quality | string | ❌ | Image quality: "auto", "high", "medium", "low", "hd", "standard" |
style | string | ❌ | Image style: "natural", "vivid" |
response_format | string | ❌ | Response format: "url" or "b64_json" |
background | string | ❌ | Background: "transparent", "opaque", "auto" |
output_format | string | ❌ | Output format: "png", "webp", "jpeg" |
output_compression | int | ❌ | Compression level (0-100%) |
partial_images | int | ❌ | Number of partial images (0-3) |
moderation | string | ❌ | Moderation level: "low", "auto" |
user | string | ❌ | User identifier |
Request Conversion
OpenAI is the baseline schema for image generation. Parameters are passed through with minimal conversion:
- Model & Prompt:
bifrostReq.Model → req.Model, bifrostReq.Prompt → req.Prompt
- Parameters: All fields from
bifrostReq (ImageGenerationParameters) are embedded directly into the OpenAI request struct via struct embedding. No field mapping or transformation is performed.
- Streaming: When streaming is requested,
stream: true is set in the request body.
Response Conversion
-
Non-streaming: OpenAI responses are unmarshaled directly into
BifrostImageGenerationResponse since Bifrost’s response schema is a superset of OpenAI’s format. All fields are passed through as-is.
-
Streaming: OpenAI streaming responses use Server-Sent Events (SSE) format with event types:
image_generation.partial_image: Intermediate image chunks with b64_json dataimage_generation.completed: Final chunk for each image with usage informationerror: Error events
Each chunk includes:
type: Event typesequence_number: Sequence number of the chunkpartial_image_index: Image index (0-N) for partial imagesb64_json: Base64-encoded image data (pointer, may be nil)usage: Token usage (only in completed events)created_at, size, quality, background, output_format: Additional metadata
Bifrost converts these to BifrostImageGenerationStreamResponse chunks with:
- Per-image
chunkIndex tracking for proper ordering within each image
Index field indicating which image (0-N) the chunk belongs toPartialImageIndex set only for partial images (not completed events)- Usage information attached to completed chunks
- Latency tracking per chunk
Endpoint: /v1/images/generations
8. Image Edit
Requests use multipart/form-data, not JSON.
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier |
prompt | string | ✅ | Text description of the edit |
image[] | binary | ✅ | Image file(s) to edit (multipart form-data, supports multiple images) |
mask | binary | ❌ | Mask image file (multipart form-data) |
n | int | ❌ | Number of images to generate (1-10) |
size | string | ❌ | Image size: "256x256", "512x512", "1024x1024", "1536x1024", "1024x1536", "auto" |
quality | string | ❌ | Image quality: "auto", "high", "medium", "low", "standard" |
response_format | string | ❌ | Response format: "url" or "b64_json" |
background | string | ❌ | Background: "transparent", "opaque", "auto" |
input_fidelity | string | ❌ | Input fidelity: "low", "high" |
partial_images | int | ❌ | Number of partial images (0-3) |
output_format | string | ❌ | Output format: "png", "webp", "jpeg" |
output_compression | int | ❌ | Compression level (0-100%) |
user | string | ❌ | User identifier |
stream | bool | ❌ | Enable streaming response |
Request Conversion
- Model & Input:
bifrostReq.Model → req.Model, bifrostReq.Input.Images → req.Input.Images, bifrostReq.Input.Prompt → req.Input.Prompt
- Parameters: All fields from
bifrostReq.Params (ImageEditParameters) are embedded directly into the OpenAI request struct via struct embedding. No field mapping or transformation is performed.
- Multipart Form Data: The request is serialized as
multipart/form-data:
- Model & Prompt: Written as form fields (
model, prompt)
- Images: Each image in
Input.Images is written as a separate image[] field with proper MIME type detection (image/jpeg, image/webp, image/png) and Content-Type headers
- Mask: If present, written as a
mask field with MIME type detection and appropriate filename (mask.png, mask.jpg, mask.webp)
- Optional Parameters: All optional parameters (
n, size, quality, response_format, background, input_fidelity, partial_images, output_format, output_compression, user) are written as form fields
- Integer Conversion: Integer fields (
n, partial_images, output_compression) are converted to strings using strconv.Itoa
- Streaming: When streaming is requested,
stream: "true" is written as a form field
Response Conversion
-
Non-streaming: OpenAI responses are unmarshaled directly into
BifrostImageGenerationResponse since Bifrost’s response schema is a superset of OpenAI’s format. All fields are passed through as-is.
-
Streaming: OpenAI streaming responses use Server-Sent Events (SSE) format with event types:
image_edit.partial_image: Intermediate image chunks with b64_json dataimage_edit.completed: Final chunk for each image with usage informationerror: Error events
Each chunk includes:
type: Event type (image_edit.partial_image or image_edit.completed)sequence_number: Sequence number of the chunkpartial_image_index: Image index (0-N) for partial imagesb64_json: Base64-encoded image data (pointer, may be nil)usage: Token usage (only in completed events)
Bifrost converts these to BifrostImageGenerationStreamResponse chunks with:
- Per-image
chunkIndex tracking for proper ordering within each image
Index field indicating which image (0-N) the chunk belongs toPartialImageIndex set only for partial images (not completed events)- Usage information attached to completed chunks
- Latency tracking per chunk
- Robust handling of interleaved chunks using incomplete image tracking
Endpoint: /v1/images/edits
9. Image Variation
Requests use multipart/form-data, not JSON.
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier |
image | binary | ✅ | Image file to create variations from (multipart form-data) |
n | int | ❌ | Number of images to generate (1-10) |
size | string | ❌ | Image size: "256x256", "512x512", "1024x1024", "1792x1024", "1024x1792", "1536x1024", "1024x1536", "auto" |
response_format | string | ❌ | Response format: "url" or "b64_json" |
user | string | ❌ | User identifier |
Request Conversion
- Model & Input:
bifrostReq.Model → req.Model, bifrostReq.Input.Image.Image → req.Input.Image.Image
- Parameters: All fields from
bifrostReq.Params (ImageVariationParameters) are embedded directly into the OpenAI request struct via struct embedding. No field mapping or transformation is performed.
- Multipart Form Data: The request is serialized as
multipart/form-data:
- Model: Written as form field (
model)
- Image: The image is written as an
image field with proper MIME type detection (image/jpeg, image/webp, image/png) and Content-Type headers. If MIME type cannot be detected, defaults to image/png
- Optional Parameters: All optional parameters (
n, size, response_format, user) are written as form fields
- Integer Conversion: Integer field (
n) is converted to string using strconv.Itoa
- Multiple Images: Additional images beyond the first one (if present in
ExtraParams["images"]) are stored in ExtraParams but only the first image is sent to OpenAI (OpenAI API only supports single image input)
Response Conversion
- Non-streaming: OpenAI responses are unmarshaled directly into
BifrostImageVariationResponse (which is a type alias for BifrostImageGenerationResponse). All fields are passed through as-is.
- Streaming: Not supported for image variation requests.
Endpoint: /v1/images/variations
10. Files API
Upload
Request Parameters
| Parameter | Type | Required | Notes |
|---|
file | binary | ✅ | File to upload (multipart form-data) |
purpose | string | ✅ | batch, fine-tune, or assistants |
filename | string | ❌ | Custom filename (defaults to file.jsonl) |
FileObject with id, bytes, created_at, filename, purpose, status (docs)
List Files
Query Parameters
| Parameter | Type | Required | Notes |
|---|
purpose | string | ❌ | Filter by purpose |
limit | int | ❌ | Results per page |
after | string | ❌ | Pagination cursor |
order | string | ❌ | asc or desc |
has_more flag.
Retrieve / Delete / Content
Operations:
- GET
/v1/files/{file_id} - Retrieve file metadata
- DELETE
/v1/files/{file_id} - Delete file
- GET
/v1/files/{file_id}/content - Download file content
11. Batch API
Create Batch
Request Parameters
| Parameter | Type | Required | Notes |
|---|
input_file_id | string | Conditional | File ID OR requests array (not both) |
requests | array | Conditional | BatchRequestItem objects (converted to JSONL) |
endpoint | string | ✅ | Target endpoint (e.g., /v1/chat/completions) |
completion_window | string | ❌ | 24h (default) |
metadata | object | ❌ | Custom metadata |
BifrostBatchCreateResponse with id, endpoint, input_file_id, status, created_at, request_counts (docs). Statuses: BatchStatus (validating, failed, in_progress, finalizing, completed, expired, cancelling, cancelled)
List Batches
Query Parameters
| Parameter | Type | Required | Notes |
|---|
limit | int | ❌ | Results per page |
after | string | ❌ | Pagination cursor |
Retrieve / Cancel Batch
Operations:
Get Results
- Batch must be
completed (has output_file_id)
- Download output file via Files API
- Parse JSONL - each
BatchResultItem: {id, custom_id, response: {status_code, body}}
12. List Models
GET /v1/models - Lists available models with metadata. Model IDs in Bifrost responses are prefixed with openai/ (e.g., openai/gpt-4o). Results are aggregated from all configured API keys. No request body or parameters required.
13. Video Generation
Generate (POST /v1/videos)
Request Parameters
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | e.g., sora-2 |
prompt | string | ✅ | Text description of the video |
input_reference | string | ❌ | Input image for image-to-video. Must be a base64 data URL (e.g., data:image/png;base64,...). Plain URLs are not accepted. |
seconds | string | ❌ | Duration in seconds |
size | string | ❌ | Resolution: 720x1280 (default), 1280x720, 1024x1792, 1792x1024 |
BifrostVideoGenerationResponse - id, status, model, prompt, created_at
Job Statuses: queued → in_progress → completed / failed
Retrieve / Download / Delete / List / Remix
| Operation | Endpoint | Notes |
|---|
| Get status | GET /v1/videos/{id} | Poll until status: completed |
| Download | GET /v1/videos/{id}/content | Returns raw video bytes |
| Delete | DELETE /v1/videos/{id} | Removes video job |
| List jobs | GET /v1/videos | Query params: after, limit, order |
| Remix | POST /v1/videos/{id}/remix | Body: {"prompt": "..."} |
14. Context Compaction
Compresses a conversation into an opaque encrypted item that can be reused in future Responses API calls, reducing token costs for long-running conversations.
Request Parameters
| Parameter | Type | Required | Notes |
|---|
model | string | ✅ | Model identifier |
input | string/array | ✅* | Conversation to compact. Required unless previous_response_id is set. Accepts the same format as the Responses API input field, including prior compaction items (type: "response.compaction"). |
previous_response_id | string | ✅* | ID of a previously stored response to compact instead of sending full input. |
instructions | string | ❌ | System instructions preserved across the compacted context. |
prompt_cache_key | string | ❌ | Prompt caching key. |
prompt_cache_retention | string | ❌ | Cache retention duration. |
service_tier | string | ❌ | Service tier preference. |
fallbacks | array | ❌ | Bifrost fallback model list. |
POST /v1/responses/compact
Common Error Codes
HTTP Status → Error Type mapping:
400 - invalid_request_error401 - authentication_error403 - permission_error404 - not_found_error429 - rate_limit_error500 - api_error