Overview
Budgeting and rate limiting are a core feature of Bifrost’s governance system managed through Virtual Keys. Bifrost’s budget management system provides comprehensive cost control and financial governance for enterprise AI deployments. It operates through a hierarchical budget structure that enables granular cost management, usage tracking, and financial oversight across your entire organization. Core Hierarchy:- Virtual Keys - Primary access control via
x-bf-vkheader (exclusive team OR customer attachment) - Budget Management - Independent budget limits at each hierarchy level with cumulative checking
- Rate Limiting - Request and token-based throttling at both VK and provider config levels
- Provider-Level Governance - Granular budgets and rate limits per AI provider within a virtual key
- Model/Provider Filtering - Granular access control per virtual key
- Usage Tracking - Real-time monitoring and audit trails
- Audit Headers - Optional team and customer identification
Budget Management
Cost Calculation
Bifrost automatically calculates costs based on:- Provider Pricing - Real-time model pricing data
- Token Usage - Input + output tokens from API responses
- Request Type - Different pricing for chat, text, embedding, speech, transcription
- Cache Status - Reduced costs for cached responses
- Batch Operations - Volume discounts for batch requests
Budget Checking Flow
When a request is made with a virtual key, Bifrost checks all applicable budgets independently in the hierarchy. Each budget must have sufficient remaining balance for the request to proceed. Checking Sequence: For VK → Team → Customer:- All applicable budgets must pass - any single budget failure blocks the request
- Budgets are independent - each tracks its own usage and limits
- Costs are deducted from all applicable budgets - same cost applied to each level
- Rate limits checked at provider config and VK levels - teams and customers have no rate limits
- Provider selection - providers that exceed their budget or rate limits are excluded from routing
Rate Limiting
Rate limits protect your system from abuse and manage traffic by setting thresholds on request frequency and token usage over a specific time window. Rate limits can be configured at both the Virtual Key level and Provider Config level for granular control. Bifrost supports two types of rate limits that work in parallel:- Request Limits: Control the maximum number of API calls that can be made within a set duration (e.g., 100 requests per minute).
- Token Limits: Control the maximum number of tokens (prompt + completion) that can be processed within a set duration (e.g., 50,000 tokens per hour).
Rate Limit Hierarchy
Rate limits are checked in hierarchical order:Provider-Level Rate Limiting
Provider configs within a virtual key can have independent rate limits, enabling:- Per-Provider Throttling: Different rate limits for OpenAI vs Anthropic
- Provider Isolation: Rate limit violations on one provider don’t affect others
- Granular Control: Fine-tune limits based on provider capabilities and costs
Reset Durations
Budgets and rate limits support flexible reset durations: Format Examples:1m- 1 minute5m- 5 minutes1h- 1 hour1d- 1 day1w- 1 week1M- 1 month1Y- 1 year
- Rate Limits:
1m,1h,1dfor request throttling - Budgets:
1d,1w,1M,1Yfor cost control
Calendar-aligned budgets
By default, a budget rolls: afterreset_duration elapses since last_reset, usage resets. With calendar_aligned: true, the budget resets at the start of each calendar period in UTC instead (same instant for every customer of that configuration).
Supported reset_duration suffixes: only day (d), week (w), month (M), and year (Y). Examples: 1d → midnight UTC each day; 1w → Monday 00:00 UTC each week; 1M → first day of each month; 1Y → January 1 each year. Sub-day durations (for example 1h, 30m) cannot use calendar alignment; the API rejects invalid combinations.
Calendar alignment applies to budgets on customers, teams, virtual keys, and per–provider-config budgets. You can set it when creating a budget (calendar_aligned on create) or toggle it on update (calendar_aligned on the budget in PUT requests). Turning calendar alignment on for an existing budget resets current usage to zero and snaps last_reset to the current period start.
Budget overrides
A budget can carry a temporary override that adds spending capacity on top of its configured limit without touching the base limit, current usage, or reset schedule. While an override is active, enforcement uses:PUT/DELETE on /api/governance/virtual-keys/{vk_id}/budgets/{budget_id}/override — see Budget Overrides for the UI walkthrough and API examples.
Customer-scoped requests
Customer scoping is a Bifrost Enterprise feature. It applies to requests made with a team-attached virtual key when that team is linked to more than one customer.
When a scope header is present, only the named customer is charged, rate-limited, and recorded in that request’s usage logs — the team’s other customers are left untouched. The team’s own budget, the virtual key budget, and provider-config limits are always enforced regardless of scope.
Resolution rules:
x-bf-customer-idtakes precedence overx-bf-customer-namewhen both are sent.- Surrounding whitespace is trimmed, and the header name is case-insensitive (like all Bifrost headers).
- Send no customer-scope header to charge and enforce all of the team’s customers (the default).
Examples
Scope a chat request to a customer by ID:Validation
The customer scope is validated before the request reaches a provider, and it fails closed: an invalid scope is rejected even when budget and rate-limit enforcement is otherwise skipped. A request is rejected with 400 Bad Request when the scope header is:- present but empty or whitespace-only,
- an ID or name that does not match any customer, or
- a customer that exists but is not attached to the virtual key’s team.
Configuration Guide
Configure provider-level budgets and rate limits using any of these methods:- Web UI
- API
- config.json
The Bifrost Web UI provides an intuitive interface for configuring provider-level governance through the Virtual Keys management page.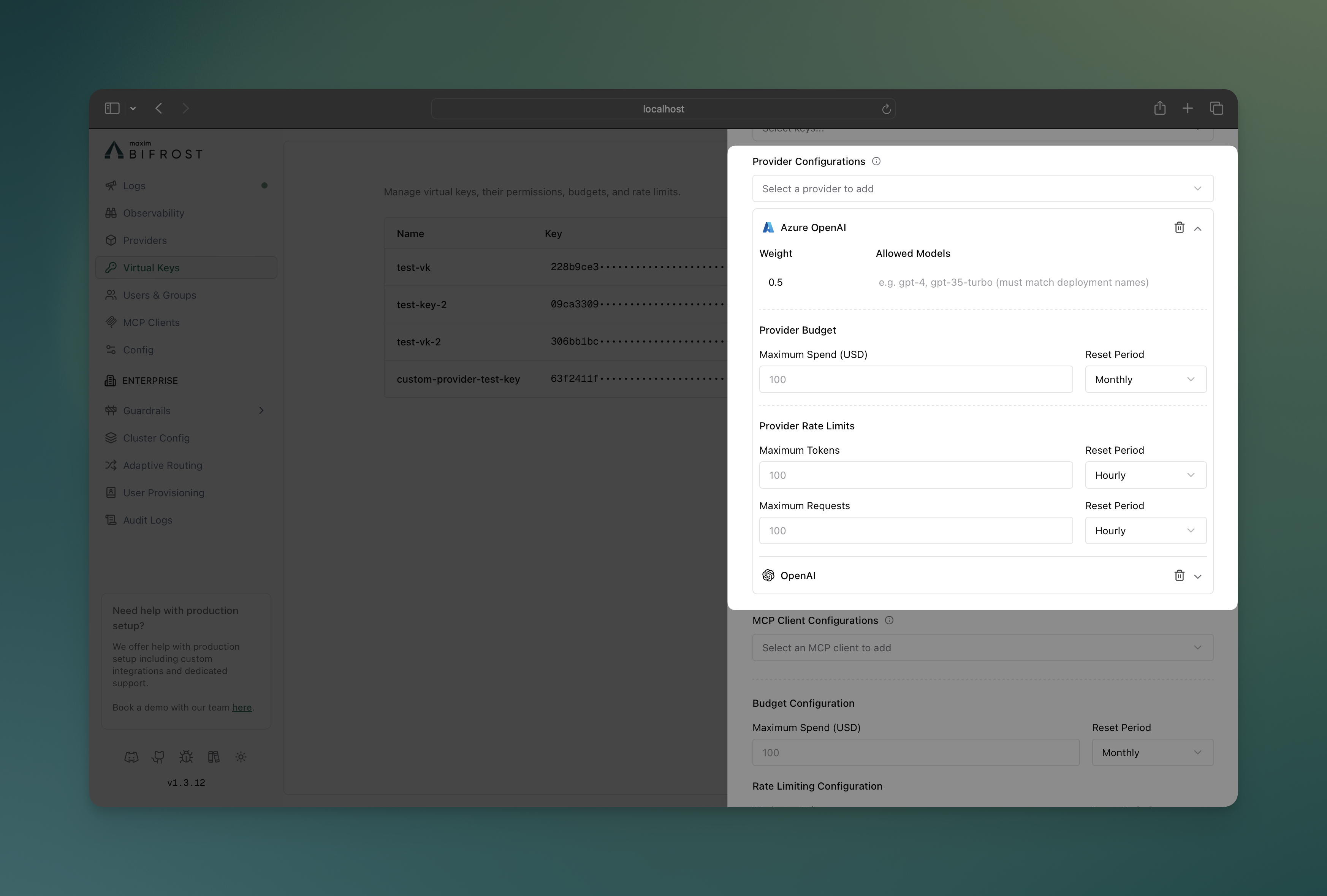
Creating Virtual Keys with Provider Configs
- Navigate to Virtual Keys: Go to Virtual Keys page in the Bifrost dashboard
- Create New Virtual Key: Click “Create Virtual Key” button
- Configure Providers: In the “Provider Configurations” section:
- Add multiple providers with individual weights
- Set provider-specific budgets and rate limits
- Configure allowed models per provider
Provider Configuration Interface
- Visual Provider Cards: Each provider displays as an expandable card
- Budget Controls: Set spending limits with reset periods per provider
- Rate Limit Controls: Configure token and request limits independently
- Model Filtering: Specify allowed models for each provider
- Weight Distribution: Visual indicators for load balancing weights
- Real-time Validation: Immediate feedback on configuration errors
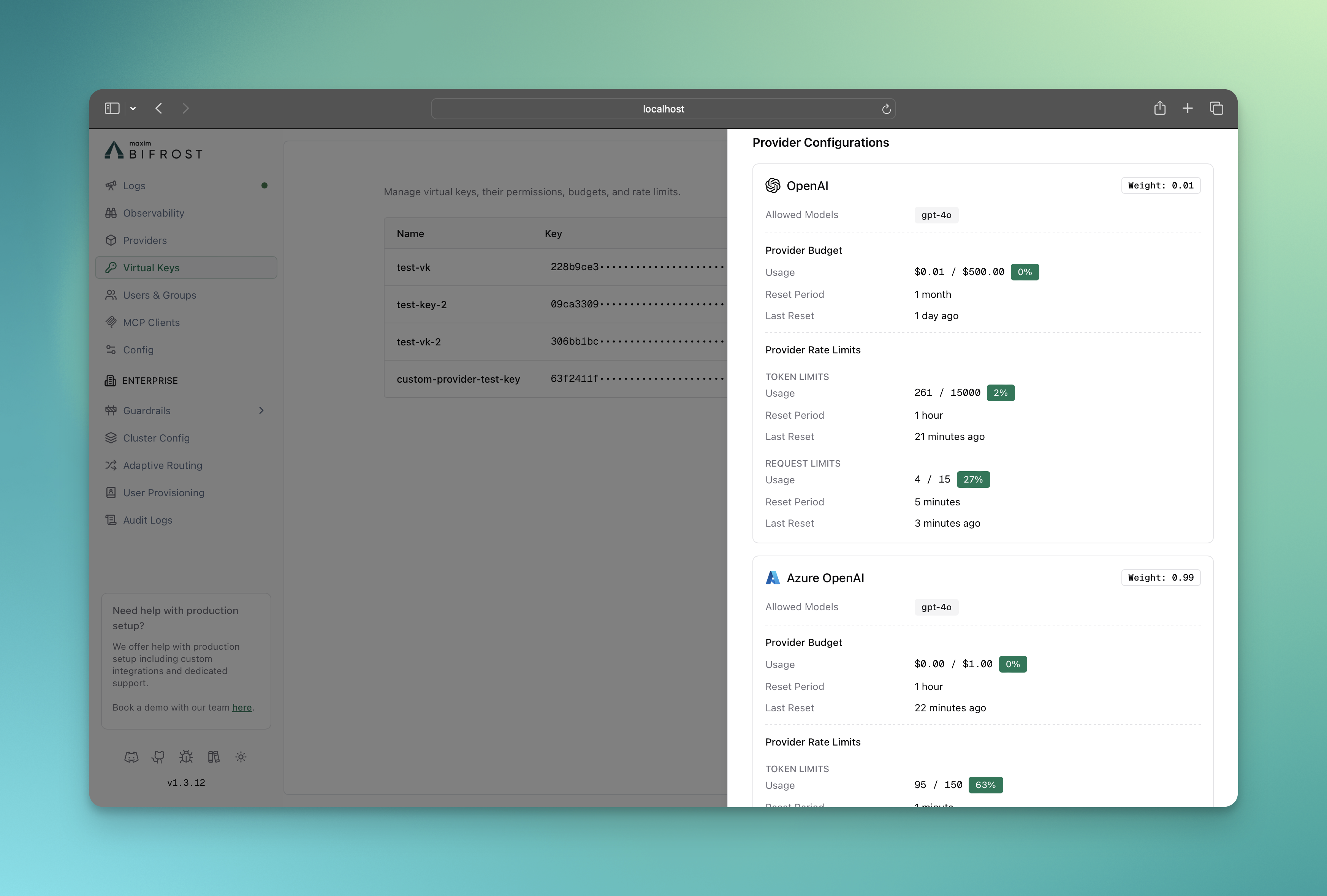
Monitoring Provider Usage
- Budget consumption per provider
- Rate limit utilization (tokens and requests)
- Provider availability status
- Usage trends and forecasting
Provider-Level Governance Examples
Example 1: Mixed Provider Budgets
A virtual key configured with multiple providers and different budget allocations:- OpenAI requests limited to 50 dollars/month at provider level + 100 dollars/month at VK level
- Anthropic requests limited to 30 dollars/month at provider level + 100 dollars/month at VK level
- If any provider’s budget is exhausted, all requests to that provider will be blocked
Example 2: Provider-Specific Rate Limits
Different rate limits based on provider capabilities:- OpenAI: 1000 requests/hour, 1M tokens/hour
- Anthropic: 500 requests/hour, 500K tokens/hour
- If any provider’s rate limits are exceeded, all requests to that provider will be blocked
Example 3: Failover Strategy
Provider configurations with budget-based failover:- Primary: Use cheap provider until $10 daily budget exhausted
- Fallback: Automatically switch to premium provider when cheap option unavailable. To enable this, you should not send
providername in the request body, read Routing for more details. - Cost containment: Prevent unexpected overspend on premium resources and limit the number of requests to the premium provider
Key Benefits of Provider-Level Governance
- Granular Control: Set specific spending limits and rate limits per AI provider
- Automatic Fallback: Route to alternative providers when budgets or rate limits are exceeded
- Cost Control: Track and control spending by provider for better financial oversight
- Performance Testing: A/B testing across providers with controlled budgets
- Multi-Provider Strategies: Primary/backup provider configurations
- Cost-Tiered Access: Cheap providers for basic tasks, premium for complex workloads
Next Steps
- Routing - Direct requests to specific AI models, providers, and keys using Virtual Keys.
- MCP Tool Filtering - Manage MCP clients/tools for virtual keys.
- Tracing - Audit trails and request tracking