> ## Documentation Index
> Fetch the complete documentation index at: https://docs.getbifrost.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Anthropic
> Anthropic API conversion guide - structural differences, message handling, thinking/reasoning, and tool conversion
## Overview
Anthropic has significant structural differences from OpenAI's format. Bifrost performs extensive conversion including:
* **System message extraction** - Removed from messages array, placed in separate `system` field
* **Tool message grouping** - Consecutive tool messages merged into single user message
* **Thinking block transformation** - `reasoning` parameters mapped to Anthropic's `thinking` structure
* **Parameter renaming** - e.g., `max_completion_tokens` → `max_tokens`, `stop` → `stop_sequences`
* **Content format conversion** - Images, files, and other content types adapted to Anthropic's schema
### Supported Operations
| Operation | Non-Streaming | Streaming | Endpoint |
| -------------------- | ------------- | --------- | ---------------------- |
| Chat Completions | ✅ | ✅ | `/v1/messages` |
| Responses API | ✅ | ✅ | `/v1/messages` |
| Text Completions | ✅ | ❌ | `/v1/complete` |
| Embeddings | ❌ | ❌ | - |
| Speech (TTS) | ❌ | ❌ | - |
| Transcriptions (STT) | ❌ | ❌ | - |
| Image Generation | ❌ | ❌ | - |
| Files | ✅ | - | `/v1/files` |
| Batch | ✅ | - | `/v1/messages/batches` |
| List Models | ✅ | - | `/v1/models` |
**Unsupported Operations** (❌): Embeddings, Speech, Transcriptions, and Image Generation are not supported by the upstream Anthropic API. These return `UnsupportedOperationError`.
## Setup & Configuration
Configure Anthropic as a provider.
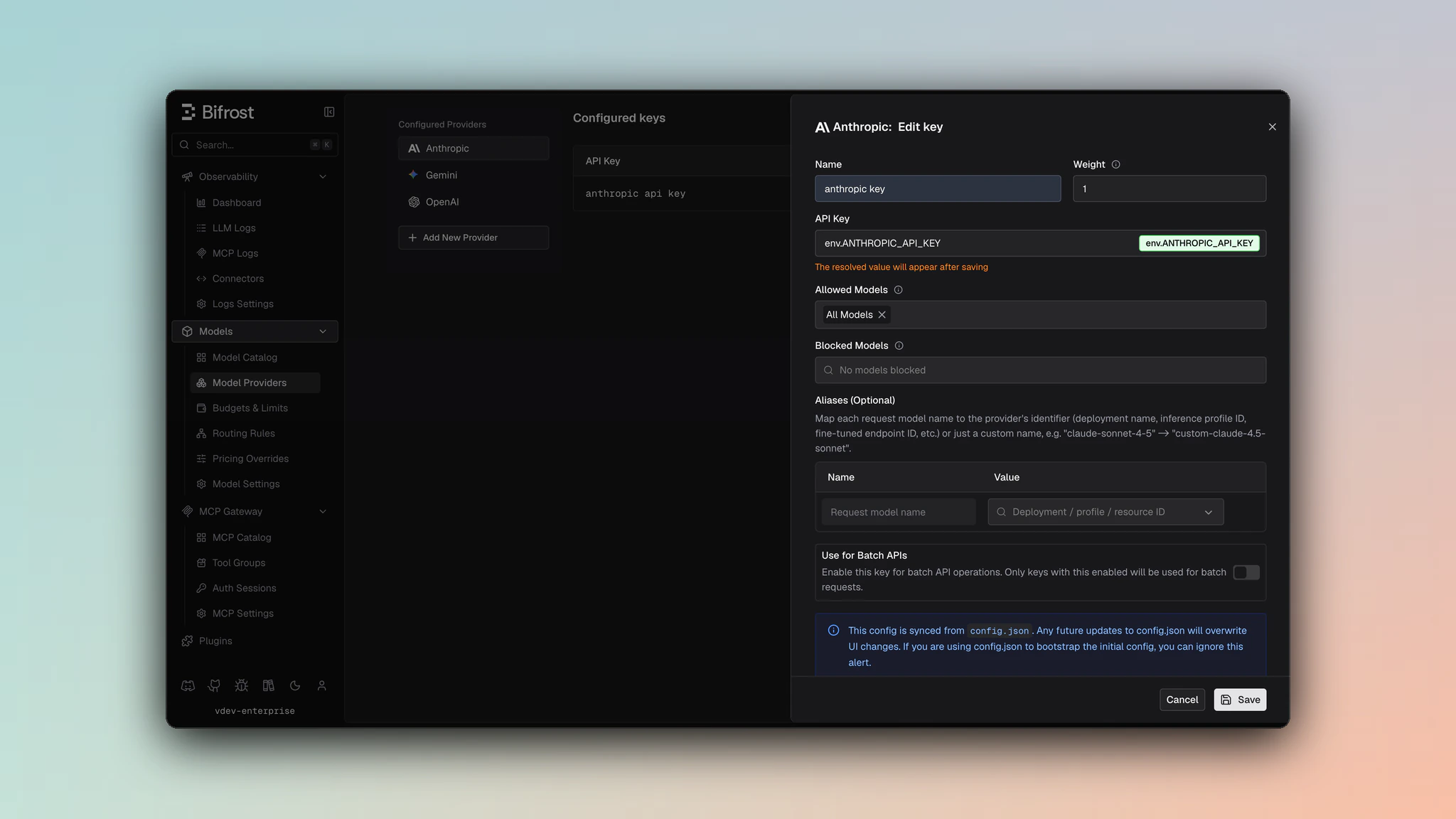 1. Navigate to **Models** > **Model Providers**. Look for **Anthropic** under **Configured Providers**. If it is missing, click on **Add New Provider** and select **Anthropic**.
2. Click **Add Key** or edit an existing key.
3. Set a name for your key.
4. Paste your API key directly or use an environment variable (for example, `env.ANTHROPIC_API_KEY`).
5. Set **Allowed Models** to **All Models** (default) or the specific model allowlist you want this key to serve.
6. Save the provider configuration.
```json theme={null}
{
"providers": {
"anthropic": {
"keys": [
{
"name": "anthropic-key-1",
"value": "env.ANTHROPIC_API_KEY",
"models": [
"*"
],
"weight": 1.0
}
]
}
}
}
```
Refer to the API documentation for [Provider Keys Management](https://docs.getbifrost.ai/api-reference/providers/create-a-key-for-a-provider).
```go theme={null}
case schemas.Anthropic:
return []schemas.Key{{
Name: "anthropic-key-1",
Value: *schemas.NewEnvVar("env.ANTHROPIC_API_KEY"),
Models: []string{"*"},
Weight: 1.0,
}}, nil
```
Use `network_config.beta_header_overrides` when you need to override the default Anthropic beta-header support matrix for a provider.
## Beta Headers
Bifrost automatically manages Anthropic beta headers - detecting required headers from request features and injecting them. Headers are validated per provider to prevent unsupported headers from reaching the upstream API.
| Beta Header | Anthropic | Azure | Vertex | Bedrock | Auto-Injected |
| ----------------------------------------------------- | --------- | ----- | ------ | ------- | --------------------------------------------------- |
| `computer-use-2025-01-24` / `computer-use-2025-11-24` | ✅ | ✅ | ✅ | ✅ | ✅ (tool type detection) |
| `structured-outputs-2025-11-13` | ✅ | ✅ | ❌ | ✅ | ✅ (strict/output\_format) |
| `advanced-tool-use-2025-11-20` | ✅ | ✅ | ❌ | ❌ | ✅ (defer\_loading/input\_examples/allowed\_callers) |
| `mcp-client-2025-11-20` | ✅ | ✅ | ❌ | ❌ | ✅ (mcp\_servers detection) |
| `prompt-caching-scope-2026-01-05` | ✅ | ✅ | ❌ | ❌ | ✅ (cache\_control.scope) |
| `compact-2026-01-12` | ✅ | ✅ | ✅ | ✅ | ✅ (compaction edit) |
| `context-management-2025-06-27` | ✅ | ✅ | ✅ | ✅ | ✅ (clear edits) |
| `files-api-2025-04-14` | ✅ | ✅ | ❌ | ❌ | ✅ (files endpoint) |
| `interleaved-thinking-2025-05-14` | ✅ | ✅ | ✅ | ✅ | ✅ (thinking enabled/adaptive) |
| `skills-2025-10-02` | ✅ | ✅ | ❌ | ❌ | Passthrough |
| `context-1m-2025-08-07` | ✅ | ✅ | ✅ | ✅ | Passthrough |
| `fast-mode-2026-02-01` | ✅ | ❌ | ❌ | ❌ | ✅ (speed=fast) |
| `redact-thinking-2026-02-12` | ✅ | ✅ | ❌ | ❌ | Passthrough |
**Passthrough headers** are not auto-injected but are validated and forwarded when set manually via the `anthropic-beta` request header. Unknown headers are forwarded to Anthropic only; for other providers (Vertex, Bedrock, Azure), unknown headers are silently dropped by default to prevent upstream errors.
**Beta header overrides**: You can override the default support per provider via the Beta Headers tab in provider configuration, or by setting `beta_header_overrides` in the provider's `network_config`. See [Beta Header Overrides](/quickstart/gateway/provider-configuration#beta-header-overrides) for details.
***
# 1. Chat Completions
## Request Parameters
### Parameter Mapping
| Parameter | Transformation |
| ----------------------- | ----------------------------------------------------------------------- |
| `max_completion_tokens` | Renamed to `max_tokens` |
| `temperature`, `top_p` | Direct pass-through |
| `stop` | Renamed to `stop_sequences` |
| `response_format` | Converted to `output_format` |
| `tools` | Schema restructured (see [Tool Conversion](#tool-conversion)) |
| `tool_choice` | Type mapped (see [Tool Conversion](#tool-conversion)) |
| `reasoning` | Mapped to `thinking` (see [Reasoning / Thinking](#reasoning--thinking)) |
| `user` | Wrapped in `metadata.user_id` |
| `top_k` | Via `extra_params` (Anthropic-specific) |
### Dropped Parameters
The following parameters are silently ignored: `frequency_penalty`, `presence_penalty`, `logit_bias`, `logprobs`, `top_logprobs`, `seed`, `parallel_tool_calls`, `service_tier`
### Extra Parameters
Use `extra_params` (SDK) or pass directly in request body (Gateway) for Anthropic-specific fields:
```bash theme={null}
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"messages": [{"role": "user", "content": "Hello"}],
"top_k": 40
}'
```
```go theme={null}
resp, err := client.ChatCompletionRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostChatRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: messages,
Params: &schemas.ChatParameters{
ExtraParams: map[string]interface{}{
"top_k": 40,
},
},
})
```
Anthropic also accepts a top-level `"cache_control": {"type": "ephemeral"}` object on `/anthropic/v1/messages` requests to enable automatic prompt caching, and Bifrost now forwards that directive through unchanged.
### Cache Control
Cache directives can be added to system messages, user messages, and tool definitions to enable prompt caching:
```bash theme={null}
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "This is cached context",
"cache_control": {"type": "ephemeral"}
}
]
}
],
"system": [
{
"type": "text",
"text": "You are a helpful assistant",
"cache_control": {"type": "ephemeral"}
}
]
}'
```
```go theme={null}
resp, err := client.ChatCompletionRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostChatRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleUser,
Content: &schemas.ChatMessageContent{
ContentBlocks: []schemas.ChatContentBlock{
{
Text: schemas.Ptr("This is cached context"),
CacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
},
},
},
},
SystemMessages: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleSystem,
Content: &schemas.ChatMessageContent{
ContentBlocks: []schemas.ChatContentBlock{
{
Text: schemas.Ptr("You are a helpful assistant"),
CacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
},
},
},
},
})
```
## Reasoning / Thinking
**Documentation**: See [Bifrost Reasoning Reference](/providers/reasoning)
### Parameter Mapping
* `reasoning.effort` → `thinking.type` (always mapped to `"enabled"`)
* `reasoning.max_tokens` → `thinking.budget_tokens` (token budget for thinking)
### Critical Constraints
* **Minimum budget**: 1024 tokens required; requests below this **fail with error**
* **Dynamic budget**: `-1` is converted to `1024` automatically
### Example
```json theme={null}
// Request
{"reasoning": {"effort": "high", "max_tokens": 2048}}
// Anthropic conversion
{"thinking": {"type": "enabled", "budget_tokens": 2048}}
```
## Message Conversion
### Critical Caveats
* **System message extraction**: System messages are **removed from messages array** and placed in separate `system` field. Multiple system messages become separate text blocks in the system array.
* **Tool message grouping**: Consecutive tool messages are **merged into single user message** with `tool_result` content blocks.
### Image Conversion
* **URL images**: `{"type": "image_url", "image_url": {}}` → `{"type": "image", "source": {"type": "url", ...}}`
* **Base64 images**: Data URL → `{"type": "image", "source": {"type": "base64", "media_type": "image/png", ...}}`
### Cache Control Locations
Cache directives supported on: system content blocks, user message content blocks, tool definitions (see [Cache Control](#cache-control) examples above)
## Tool Conversion
Tool definitions are restructured: `function.name` → `name`, `function.parameters` → `input_schema`, `function.strict` is dropped.
Tool choice mapping: `"auto"` → `auto` | `"none"` → `none` | `"required"` → `any` | Specific tool → `{"type": "tool", "name": "X"}`
## Response Conversion
### Field Mapping
* `stop_reason` → `finish_reason`: `end_turn`/`stop_sequence` → `stop`, `max_tokens` → `length`, `tool_use` → `tool_calls`
* `input_tokens + cache_read_input_tokens + cache_creation_input_tokens` → `prompt_tokens` (all cache counts rolled into the total)
* Cache token breakdown surfaced in `prompt_tokens_details`:
* `cache_read_input_tokens` → `prompt_tokens_details.cached_read_tokens`
* `cache_creation_input_tokens` → `prompt_tokens_details.cached_write_tokens`
* `output_tokens` → `completion_tokens`
* `thinking` blocks → `reasoning_details` with index, type, text, and signature fields
* Tool call arguments converted from JSON object → JSON string
## Streaming
Event sequence: `message_start` → `content_block_start` → `content_block_delta` → `content_block_stop` → `message_delta` → `message_stop`
Delta types: `text_delta` → content | `input_json_delta` → tool arguments | `thinking_delta` → reasoning text | `signature_delta` → reasoning signature
***
## Caveats
**Severity**: High
**Behavior**: System messages removed from array, placed in separate `system` field
**Impact**: Message array structure differs from input
**Code**: `chat.go:145-167`
**Severity**: High
**Behavior**: Consecutive tool messages merged into single user message
**Impact**: Message count and structure changes
**Code**: `chat.go:169-216`
**Severity**: High
**Behavior**: `reasoning.max_tokens` must be >= 1024
**Impact**: Requests with lower values **fail with error**
**Code**: `chat.go:113-115`
**Severity**: Medium
**Behavior**: `reasoning.max_tokens = -1` converted to `1024`
**Impact**: Dynamic budgeting not supported
**Code**: `chat.go:107-111`
**Severity**: Medium
**Behavior**: `strict: true` in tool definitions silently dropped
**Impact**: No schema validation enforcement
**Code**: `chat.go:43-72`
**Severity**: Low
**Behavior**: Tool call `input` (object) serialized to `arguments` (JSON string)
**Code**: `chat.go:341-350`
***
# 2. Responses API
The Responses API uses the same underlying `/v1/messages` endpoint but converts between OpenAI's Responses format and Anthropic's Messages format.
## Request Parameters
### Parameter Mapping
| Parameter | Transformation |
| ---------------------- | ----------------------------------------------------------------------- |
| `max_output_tokens` | Renamed to `max_tokens` |
| `temperature`, `top_p` | Direct pass-through |
| `instructions` | Becomes system message |
| `tools` | Schema restructured (see [Chat Completions](#1-chat-completions)) |
| `tool_choice` | Type mapped (see [Chat Completions](#1-chat-completions)) |
| `reasoning` | Mapped to `thinking` (see [Reasoning / Thinking](#reasoning--thinking)) |
| `user` | Wrapped in `metadata.user_id` |
| `text` | Converted to `output_format` |
| `include` | Via `extra_params` (Anthropic-specific) |
| `stop` | Via `extra_params`, renamed to `stop_sequences` |
| `top_k` | Via `extra_params` (Anthropic-specific) |
| `truncation` | Auto-set to `"auto"` for computer tools |
### Extra Parameters
Use `extra_params` (SDK) or pass directly in request body (Gateway):
```bash theme={null}
curl -X POST http://localhost:8080/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"input": "Hello, how are you?",
"top_k": 40
}'
```
```go theme={null}
resp, err := client.ResponsesRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostResponsesRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: messages,
Params: &schemas.ResponsesParameters{
ExtraParams: map[string]interface{}{
"top_k": 40,
},
},
})
```
### Cache Control
Cache directives can be added to instructions (system) and input messages to enable prompt caching:
```bash theme={null}
curl -X POST http://localhost:8080/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"instructions": "You are a helpful assistant. This instruction is cached.",
"instructions_cache_control": {"type": "ephemeral"},
"input": [
{
"type": "text",
"text": "Answer this question",
"cache_control": {"type": "ephemeral"}
}
]
}'
```
```go theme={null}
resp, err := client.ResponsesRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostResponsesRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleUser,
Content: &schemas.ChatMessageContent{
ContentBlocks: []schemas.ChatContentBlock{
{
Text: schemas.Ptr("Answer this question"),
CacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
},
},
},
},
Params: &schemas.ResponsesParameters{
Instructions: schemas.Ptr("You are a helpful assistant. This instruction is cached."),
InstructionsCacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
})
```
## Input & Instructions
* **Input**: String wrapped as user message or array converted to messages
* **Instructions**: Becomes system message (same extraction as [Chat Completions](#1-chat-completions))
## Tool Support
Supported types: `function`, `computer_use_preview`, `web_search`, `mcp`
Tool conversions same as [Chat Completions](#1-chat-completions) with: MCP tools mapped to `mcp_servers` (server\_label → name, server\_url → url) and computer tools auto-set with `truncation: "auto"`
Cache control supported on instructions and input blocks (see [Cache Control](#cache-control) examples)
## Response Conversion
* `stop_reason` → `status`: `end_turn`/`stop_sequence` → `completed`, `max_tokens` → `incomplete`
* Top-level `input_tokens` and `output_tokens` are rollups that include cache-related usage; they map as `input_tokens` → `input_tokens` | `output_tokens` → `output_tokens`.
* Cache-specific counts are exposed in details: `cache_read_input_tokens` → `input_tokens_details.cached_read_tokens` | `cache_creation_input_tokens` → `input_tokens_details.cached_write_tokens`
* Output items: `text` → `message` | `tool_use` → `function_call` | `thinking` → `reasoning`
## Streaming
Event sequence: `message_start` → `content_block_start` → `content_block_delta` → `content_block_stop` → `message_delta` → `message_stop`
Special handling: Computer tool arguments accumulated across chunks (emitted on `content_block_stop`), synthetic `content_part.added` events emitted for text/reasoning, MCP calls use `mcp_call_arguments_delta`, item IDs generated as `msg_{messageID}_item_{outputIndex}`
***
# 3. Text Completions (Legacy)
Legacy API using `/v1/complete` endpoint. Streaming not supported.
**Request**: `prompt` auto-wrapped with `\n\nHuman: {prompt}\n\nAssistant:` | `max_tokens` → `max_tokens_to_sample` | `temperature`, `top_p` direct pass-through | `top_k`, `stop` via `extra_params` (→ `stop_sequences`)
**Response**: `completion` → `choices[0].text` | `stop_reason` → `finish_reason`
***
# 4. Batch API
**Request formats**: `requests` array (CustomID + Params) or `input_file_id`
**Pagination**: Cursor-based with `after_id`, `before_id`, `limit`
**Endpoints**:
* POST `/v1/messages/batches` - Create
* GET `/v1/messages/batches` - List
* GET `/v1/messages/batches/{batch_id}` - Retrieve
* POST `/v1/messages/batches/{batch_id}/cancel` - Cancel
**Response**: JSONL format with `{custom_id, result: {type, message}}`
**Status mapping**: `in_progress` → `InProgress`, `canceling` → `Cancelling`, `ended` → `Ended`
**Note**: RFC3339Nano timestamps converted to Unix, multi-key retry supported
***
# 5. Files API
Requires beta header: `anthropic-beta: files-api-2025-04-14`
**Upload**: Multipart/form-data with `file` (required) and `filename` (optional)
**Field mapping**: `id` | `filename` | `size_bytes` → `bytes` | `created_at` (Unix) | `mime_type` → `content_type`
**Endpoints**: POST `/v1/files`, GET `/v1/files` (cursor pagination), GET `/v1/files/{file_id}`, DELETE `/v1/files/{file_id}`, GET `/v1/files/{file_id}/content`
**Note**: File purpose always `"batch"`, status always `"processed"`
***
# 6. List Models
**Request**: GET `/v1/models?limit={defaultPageSize}` (no body)
**Field mapping**: `id` (prefixed `anthropic/`) | `display_name` → `name` | `created_at` (Unix timestamp)
**Pagination**: Token-based with `NextPageToken`, `FirstID`, `LastID`
**Multi-key support**: Results aggregated from all keys, filtered by `allowed_models` if configured
1. Navigate to **Models** > **Model Providers**. Look for **Anthropic** under **Configured Providers**. If it is missing, click on **Add New Provider** and select **Anthropic**.
2. Click **Add Key** or edit an existing key.
3. Set a name for your key.
4. Paste your API key directly or use an environment variable (for example, `env.ANTHROPIC_API_KEY`).
5. Set **Allowed Models** to **All Models** (default) or the specific model allowlist you want this key to serve.
6. Save the provider configuration.
```json theme={null}
{
"providers": {
"anthropic": {
"keys": [
{
"name": "anthropic-key-1",
"value": "env.ANTHROPIC_API_KEY",
"models": [
"*"
],
"weight": 1.0
}
]
}
}
}
```
Refer to the API documentation for [Provider Keys Management](https://docs.getbifrost.ai/api-reference/providers/create-a-key-for-a-provider).
```go theme={null}
case schemas.Anthropic:
return []schemas.Key{{
Name: "anthropic-key-1",
Value: *schemas.NewEnvVar("env.ANTHROPIC_API_KEY"),
Models: []string{"*"},
Weight: 1.0,
}}, nil
```
Use `network_config.beta_header_overrides` when you need to override the default Anthropic beta-header support matrix for a provider.
## Beta Headers
Bifrost automatically manages Anthropic beta headers - detecting required headers from request features and injecting them. Headers are validated per provider to prevent unsupported headers from reaching the upstream API.
| Beta Header | Anthropic | Azure | Vertex | Bedrock | Auto-Injected |
| ----------------------------------------------------- | --------- | ----- | ------ | ------- | --------------------------------------------------- |
| `computer-use-2025-01-24` / `computer-use-2025-11-24` | ✅ | ✅ | ✅ | ✅ | ✅ (tool type detection) |
| `structured-outputs-2025-11-13` | ✅ | ✅ | ❌ | ✅ | ✅ (strict/output\_format) |
| `advanced-tool-use-2025-11-20` | ✅ | ✅ | ❌ | ❌ | ✅ (defer\_loading/input\_examples/allowed\_callers) |
| `mcp-client-2025-11-20` | ✅ | ✅ | ❌ | ❌ | ✅ (mcp\_servers detection) |
| `prompt-caching-scope-2026-01-05` | ✅ | ✅ | ❌ | ❌ | ✅ (cache\_control.scope) |
| `compact-2026-01-12` | ✅ | ✅ | ✅ | ✅ | ✅ (compaction edit) |
| `context-management-2025-06-27` | ✅ | ✅ | ✅ | ✅ | ✅ (clear edits) |
| `files-api-2025-04-14` | ✅ | ✅ | ❌ | ❌ | ✅ (files endpoint) |
| `interleaved-thinking-2025-05-14` | ✅ | ✅ | ✅ | ✅ | ✅ (thinking enabled/adaptive) |
| `skills-2025-10-02` | ✅ | ✅ | ❌ | ❌ | Passthrough |
| `context-1m-2025-08-07` | ✅ | ✅ | ✅ | ✅ | Passthrough |
| `fast-mode-2026-02-01` | ✅ | ❌ | ❌ | ❌ | ✅ (speed=fast) |
| `redact-thinking-2026-02-12` | ✅ | ✅ | ❌ | ❌ | Passthrough |
**Passthrough headers** are not auto-injected but are validated and forwarded when set manually via the `anthropic-beta` request header. Unknown headers are forwarded to Anthropic only; for other providers (Vertex, Bedrock, Azure), unknown headers are silently dropped by default to prevent upstream errors.
**Beta header overrides**: You can override the default support per provider via the Beta Headers tab in provider configuration, or by setting `beta_header_overrides` in the provider's `network_config`. See [Beta Header Overrides](/quickstart/gateway/provider-configuration#beta-header-overrides) for details.
***
# 1. Chat Completions
## Request Parameters
### Parameter Mapping
| Parameter | Transformation |
| ----------------------- | ----------------------------------------------------------------------- |
| `max_completion_tokens` | Renamed to `max_tokens` |
| `temperature`, `top_p` | Direct pass-through |
| `stop` | Renamed to `stop_sequences` |
| `response_format` | Converted to `output_format` |
| `tools` | Schema restructured (see [Tool Conversion](#tool-conversion)) |
| `tool_choice` | Type mapped (see [Tool Conversion](#tool-conversion)) |
| `reasoning` | Mapped to `thinking` (see [Reasoning / Thinking](#reasoning--thinking)) |
| `user` | Wrapped in `metadata.user_id` |
| `top_k` | Via `extra_params` (Anthropic-specific) |
### Dropped Parameters
The following parameters are silently ignored: `frequency_penalty`, `presence_penalty`, `logit_bias`, `logprobs`, `top_logprobs`, `seed`, `parallel_tool_calls`, `service_tier`
### Extra Parameters
Use `extra_params` (SDK) or pass directly in request body (Gateway) for Anthropic-specific fields:
```bash theme={null}
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"messages": [{"role": "user", "content": "Hello"}],
"top_k": 40
}'
```
```go theme={null}
resp, err := client.ChatCompletionRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostChatRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: messages,
Params: &schemas.ChatParameters{
ExtraParams: map[string]interface{}{
"top_k": 40,
},
},
})
```
Anthropic also accepts a top-level `"cache_control": {"type": "ephemeral"}` object on `/anthropic/v1/messages` requests to enable automatic prompt caching, and Bifrost now forwards that directive through unchanged.
### Cache Control
Cache directives can be added to system messages, user messages, and tool definitions to enable prompt caching:
```bash theme={null}
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "This is cached context",
"cache_control": {"type": "ephemeral"}
}
]
}
],
"system": [
{
"type": "text",
"text": "You are a helpful assistant",
"cache_control": {"type": "ephemeral"}
}
]
}'
```
```go theme={null}
resp, err := client.ChatCompletionRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostChatRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleUser,
Content: &schemas.ChatMessageContent{
ContentBlocks: []schemas.ChatContentBlock{
{
Text: schemas.Ptr("This is cached context"),
CacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
},
},
},
},
SystemMessages: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleSystem,
Content: &schemas.ChatMessageContent{
ContentBlocks: []schemas.ChatContentBlock{
{
Text: schemas.Ptr("You are a helpful assistant"),
CacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
},
},
},
},
})
```
## Reasoning / Thinking
**Documentation**: See [Bifrost Reasoning Reference](/providers/reasoning)
### Parameter Mapping
* `reasoning.effort` → `thinking.type` (always mapped to `"enabled"`)
* `reasoning.max_tokens` → `thinking.budget_tokens` (token budget for thinking)
### Critical Constraints
* **Minimum budget**: 1024 tokens required; requests below this **fail with error**
* **Dynamic budget**: `-1` is converted to `1024` automatically
### Example
```json theme={null}
// Request
{"reasoning": {"effort": "high", "max_tokens": 2048}}
// Anthropic conversion
{"thinking": {"type": "enabled", "budget_tokens": 2048}}
```
## Message Conversion
### Critical Caveats
* **System message extraction**: System messages are **removed from messages array** and placed in separate `system` field. Multiple system messages become separate text blocks in the system array.
* **Tool message grouping**: Consecutive tool messages are **merged into single user message** with `tool_result` content blocks.
### Image Conversion
* **URL images**: `{"type": "image_url", "image_url": {}}` → `{"type": "image", "source": {"type": "url", ...}}`
* **Base64 images**: Data URL → `{"type": "image", "source": {"type": "base64", "media_type": "image/png", ...}}`
### Cache Control Locations
Cache directives supported on: system content blocks, user message content blocks, tool definitions (see [Cache Control](#cache-control) examples above)
## Tool Conversion
Tool definitions are restructured: `function.name` → `name`, `function.parameters` → `input_schema`, `function.strict` is dropped.
Tool choice mapping: `"auto"` → `auto` | `"none"` → `none` | `"required"` → `any` | Specific tool → `{"type": "tool", "name": "X"}`
## Response Conversion
### Field Mapping
* `stop_reason` → `finish_reason`: `end_turn`/`stop_sequence` → `stop`, `max_tokens` → `length`, `tool_use` → `tool_calls`
* `input_tokens + cache_read_input_tokens + cache_creation_input_tokens` → `prompt_tokens` (all cache counts rolled into the total)
* Cache token breakdown surfaced in `prompt_tokens_details`:
* `cache_read_input_tokens` → `prompt_tokens_details.cached_read_tokens`
* `cache_creation_input_tokens` → `prompt_tokens_details.cached_write_tokens`
* `output_tokens` → `completion_tokens`
* `thinking` blocks → `reasoning_details` with index, type, text, and signature fields
* Tool call arguments converted from JSON object → JSON string
## Streaming
Event sequence: `message_start` → `content_block_start` → `content_block_delta` → `content_block_stop` → `message_delta` → `message_stop`
Delta types: `text_delta` → content | `input_json_delta` → tool arguments | `thinking_delta` → reasoning text | `signature_delta` → reasoning signature
***
## Caveats
**Severity**: High
**Behavior**: System messages removed from array, placed in separate `system` field
**Impact**: Message array structure differs from input
**Code**: `chat.go:145-167`
**Severity**: High
**Behavior**: Consecutive tool messages merged into single user message
**Impact**: Message count and structure changes
**Code**: `chat.go:169-216`
**Severity**: High
**Behavior**: `reasoning.max_tokens` must be >= 1024
**Impact**: Requests with lower values **fail with error**
**Code**: `chat.go:113-115`
**Severity**: Medium
**Behavior**: `reasoning.max_tokens = -1` converted to `1024`
**Impact**: Dynamic budgeting not supported
**Code**: `chat.go:107-111`
**Severity**: Medium
**Behavior**: `strict: true` in tool definitions silently dropped
**Impact**: No schema validation enforcement
**Code**: `chat.go:43-72`
**Severity**: Low
**Behavior**: Tool call `input` (object) serialized to `arguments` (JSON string)
**Code**: `chat.go:341-350`
***
# 2. Responses API
The Responses API uses the same underlying `/v1/messages` endpoint but converts between OpenAI's Responses format and Anthropic's Messages format.
## Request Parameters
### Parameter Mapping
| Parameter | Transformation |
| ---------------------- | ----------------------------------------------------------------------- |
| `max_output_tokens` | Renamed to `max_tokens` |
| `temperature`, `top_p` | Direct pass-through |
| `instructions` | Becomes system message |
| `tools` | Schema restructured (see [Chat Completions](#1-chat-completions)) |
| `tool_choice` | Type mapped (see [Chat Completions](#1-chat-completions)) |
| `reasoning` | Mapped to `thinking` (see [Reasoning / Thinking](#reasoning--thinking)) |
| `user` | Wrapped in `metadata.user_id` |
| `text` | Converted to `output_format` |
| `include` | Via `extra_params` (Anthropic-specific) |
| `stop` | Via `extra_params`, renamed to `stop_sequences` |
| `top_k` | Via `extra_params` (Anthropic-specific) |
| `truncation` | Auto-set to `"auto"` for computer tools |
### Extra Parameters
Use `extra_params` (SDK) or pass directly in request body (Gateway):
```bash theme={null}
curl -X POST http://localhost:8080/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"input": "Hello, how are you?",
"top_k": 40
}'
```
```go theme={null}
resp, err := client.ResponsesRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostResponsesRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: messages,
Params: &schemas.ResponsesParameters{
ExtraParams: map[string]interface{}{
"top_k": 40,
},
},
})
```
### Cache Control
Cache directives can be added to instructions (system) and input messages to enable prompt caching:
```bash theme={null}
curl -X POST http://localhost:8080/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic/claude-3-5-sonnet",
"instructions": "You are a helpful assistant. This instruction is cached.",
"instructions_cache_control": {"type": "ephemeral"},
"input": [
{
"type": "text",
"text": "Answer this question",
"cache_control": {"type": "ephemeral"}
}
]
}'
```
```go theme={null}
resp, err := client.ResponsesRequest(schemas.NewBifrostContext(ctx, schemas.NoDeadline), &schemas.BifrostResponsesRequest{
Provider: schemas.Anthropic,
Model: "claude-3-5-sonnet",
Input: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleUser,
Content: &schemas.ChatMessageContent{
ContentBlocks: []schemas.ChatContentBlock{
{
Text: schemas.Ptr("Answer this question"),
CacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
},
},
},
},
Params: &schemas.ResponsesParameters{
Instructions: schemas.Ptr("You are a helpful assistant. This instruction is cached."),
InstructionsCacheControl: &schemas.CacheControl{
Type: schemas.Ptr("ephemeral"),
},
},
})
```
## Input & Instructions
* **Input**: String wrapped as user message or array converted to messages
* **Instructions**: Becomes system message (same extraction as [Chat Completions](#1-chat-completions))
## Tool Support
Supported types: `function`, `computer_use_preview`, `web_search`, `mcp`
Tool conversions same as [Chat Completions](#1-chat-completions) with: MCP tools mapped to `mcp_servers` (server\_label → name, server\_url → url) and computer tools auto-set with `truncation: "auto"`
Cache control supported on instructions and input blocks (see [Cache Control](#cache-control) examples)
## Response Conversion
* `stop_reason` → `status`: `end_turn`/`stop_sequence` → `completed`, `max_tokens` → `incomplete`
* Top-level `input_tokens` and `output_tokens` are rollups that include cache-related usage; they map as `input_tokens` → `input_tokens` | `output_tokens` → `output_tokens`.
* Cache-specific counts are exposed in details: `cache_read_input_tokens` → `input_tokens_details.cached_read_tokens` | `cache_creation_input_tokens` → `input_tokens_details.cached_write_tokens`
* Output items: `text` → `message` | `tool_use` → `function_call` | `thinking` → `reasoning`
## Streaming
Event sequence: `message_start` → `content_block_start` → `content_block_delta` → `content_block_stop` → `message_delta` → `message_stop`
Special handling: Computer tool arguments accumulated across chunks (emitted on `content_block_stop`), synthetic `content_part.added` events emitted for text/reasoning, MCP calls use `mcp_call_arguments_delta`, item IDs generated as `msg_{messageID}_item_{outputIndex}`
***
# 3. Text Completions (Legacy)
Legacy API using `/v1/complete` endpoint. Streaming not supported.
**Request**: `prompt` auto-wrapped with `\n\nHuman: {prompt}\n\nAssistant:` | `max_tokens` → `max_tokens_to_sample` | `temperature`, `top_p` direct pass-through | `top_k`, `stop` via `extra_params` (→ `stop_sequences`)
**Response**: `completion` → `choices[0].text` | `stop_reason` → `finish_reason`
***
# 4. Batch API
**Request formats**: `requests` array (CustomID + Params) or `input_file_id`
**Pagination**: Cursor-based with `after_id`, `before_id`, `limit`
**Endpoints**:
* POST `/v1/messages/batches` - Create
* GET `/v1/messages/batches` - List
* GET `/v1/messages/batches/{batch_id}` - Retrieve
* POST `/v1/messages/batches/{batch_id}/cancel` - Cancel
**Response**: JSONL format with `{custom_id, result: {type, message}}`
**Status mapping**: `in_progress` → `InProgress`, `canceling` → `Cancelling`, `ended` → `Ended`
**Note**: RFC3339Nano timestamps converted to Unix, multi-key retry supported
***
# 5. Files API
Requires beta header: `anthropic-beta: files-api-2025-04-14`
**Upload**: Multipart/form-data with `file` (required) and `filename` (optional)
**Field mapping**: `id` | `filename` | `size_bytes` → `bytes` | `created_at` (Unix) | `mime_type` → `content_type`
**Endpoints**: POST `/v1/files`, GET `/v1/files` (cursor pagination), GET `/v1/files/{file_id}`, DELETE `/v1/files/{file_id}`, GET `/v1/files/{file_id}/content`
**Note**: File purpose always `"batch"`, status always `"processed"`
***
# 6. List Models
**Request**: GET `/v1/models?limit={defaultPageSize}` (no body)
**Field mapping**: `id` (prefixed `anthropic/`) | `display_name` → `name` | `created_at` (Unix timestamp)
**Pagination**: Token-based with `NextPageToken`, `FirstID`, `LastID`
**Multi-key support**: Results aggregated from all keys, filtered by `allowed_models` if configured