> ## Documentation Index
> Fetch the complete documentation index at: https://docs.getbifrost.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Retries & Fallbacks
> Automatic retry with exponential backoff and provider failover. Retries handle transient errors within a provider; fallbacks switch to a different provider when all retries are exhausted.
## Overview
Bifrost provides two complementary layers of resilience:
* **Retries** - When a provider returns a transient server error (network issue, 5xx) or a per-key failure (`429` rate-limit, `401`/`403` auth, `402` billing), Bifrost automatically retries the same request against the same provider. Transient-server retries reuse the same key with exponential backoff; per-key failures rotate to a different API key from your pool. Backoff is skipped only when rotating away from a *permanent* per-key failure (`401`/`402`/`403`) where waiting offers nothing — for `429` rotations a backoff is still applied to let account-level quota windows slide.
* **Fallbacks** - When the primary provider fails after exhausting all retries, Bifrost moves on to the next provider in your fallback chain. Each fallback provider gets its own full retry budget.
Together, they let you build LLM-powered applications that stay up through rate limits, transient outages, and even full provider failures - with no changes required in your application code.
***
## Retries
### How retries work
When a request fails with a retryable error, Bifrost:
1. Classifies the failure as either a **per-key failure** (the credential / account is the problem — status `401`/`402`/`403`/`429`) or a **transient server failure** (the upstream is the problem — `5xx` / network / DNS).
2. On **per-key failures**, rotates to a different API key from the pool (if multiple keys are configured). Two sub-cases:
* **Permanent per-key failure** (`401`/`402`/`403`): mark the key dead for the remainder of the request and rotate immediately — **no backoff**, since waiting can't revive a bad credential.
* **Transient per-key failure** (`429` rate-limit): mark the key as used-this-cycle and rotate, but **still apply backoff** — providers often enforce account-level quotas shared across keys, so the new key may not have fresh capacity until the window slides.
3. On **transient server failures** (`5xx`, DNS, connection refused): reuse the same key and wait using **exponential backoff with jitter** before the next attempt.
4. Continues until the request succeeds, `max_retries` is exhausted, or every key is permanently dead (in which case Bifrost returns `502 upstream_credentials_exhausted` rather than the raw `4xx`, to make it clear the caller's Bifrost API key is fine — the configured provider credentials are not).
### Backoff formula
Backoff applies to **same-key retries** (transient server 5xx / network errors) and to **`429` rate-limit rotations** (since account-level quotas can be shared across keys). It is skipped only when rotating away from a **permanent per-key failure** (`401`/`402`/`403`) to a genuinely different credential — a dead key gains nothing from waiting.
```
backoff = min(retry_backoff_initial × 2^attempt, retry_backoff_max) × jitter(0.8–1.2)
```
With the defaults of `retry_backoff_initial = 500ms` and `retry_backoff_max = 5000ms`:
| Attempt | Base backoff | With jitter (approx.) |
| ---------- | ---------------- | --------------------- |
| 1st retry | 500 ms | 400–600 ms |
| 2nd retry | 1000 ms | 800 ms–1.2 s |
| 3rd retry | 2000 ms | 1.6–2.4 s |
| 4th retry | 4000 ms | 3.2–4.8 s |
| 5th+ retry | 5000 ms (capped) | 4–5 s |
### What triggers a retry
| Condition | Retried? | Key rotation? | Backoff before next attempt? |
| ------------------------------------------------ | -------- | -------------------------------------------------------------- | ---------------------------------------------------- |
| Network error (DNS, connection refused) | Yes | No - same key reused | Yes |
| `5xx` server errors (500, 502, 503, 504) | Yes | No - same key reused | Yes |
| Rate limit (`429` or rate-limit message pattern) | Yes | Yes - rate-limited key may be retried later in the cycle | Yes - account-level quotas may be shared across keys |
| Auth failure (`401`, `403`) | Yes | Yes - failing key marked **permanently dead** for this request | No - waiting can't revive a bad credential |
| Billing failure (`402`) | Yes | Yes - failing key marked **permanently dead** for this request | No - waiting can't revive a bad credential |
| Request validation error (`400`/`404`/`422`/...) | No | - | - |
| Plugin-enforced block | No | - | - |
| Cancelled request | No | - | - |
### Configuring retries
Retries are configured per-provider in `network_config`. The defaults are `max_retries: 0` (no retries), `retry_backoff_initial: 500` ms, and `retry_backoff_max: 5000` ms.
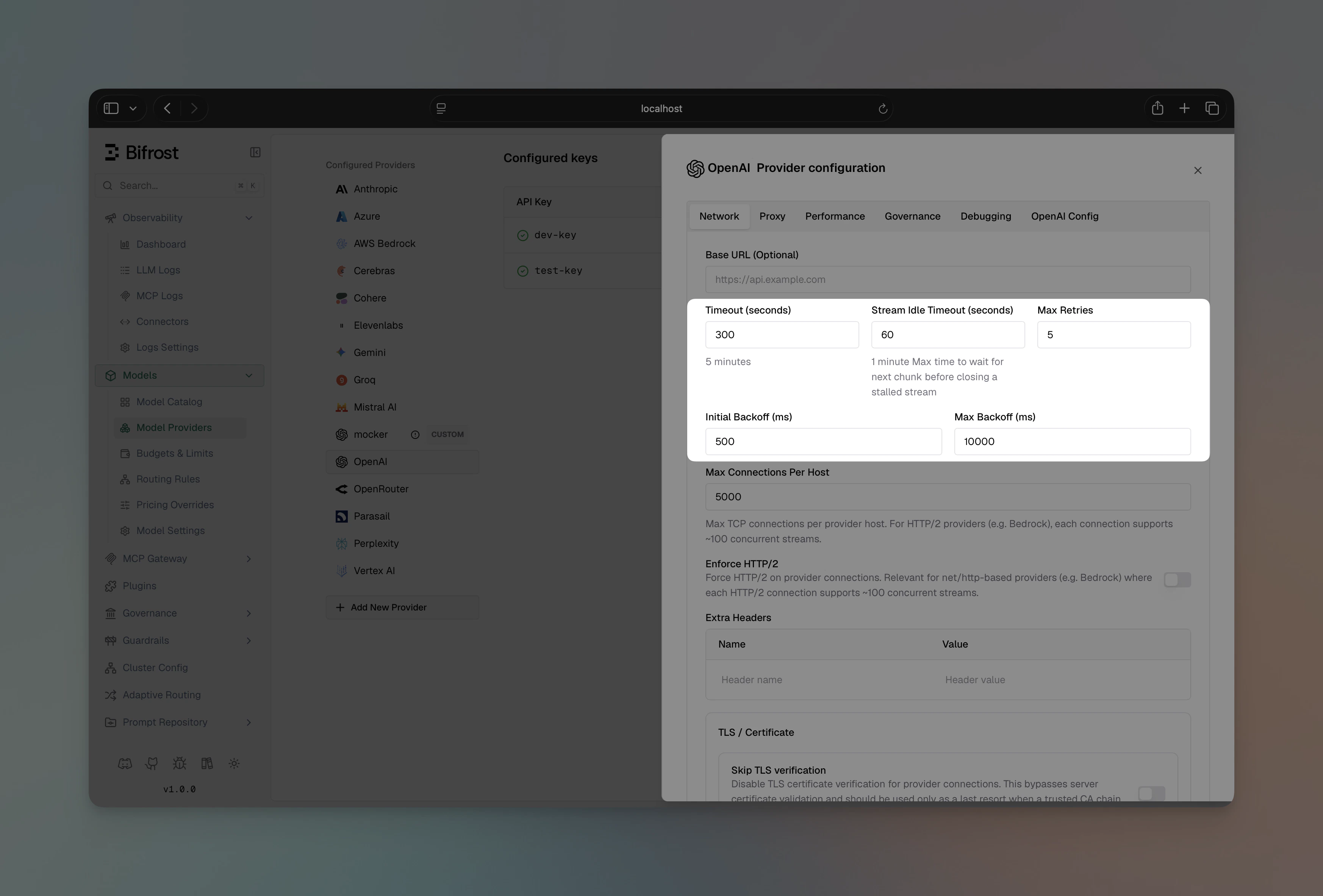 Navigate to **Providers**, select a provider, and open the **Network Config** section.
Set:
* **Max Retries** - number of additional attempts after the first failure (e.g. `3`)
* **Retry Backoff Initial** - starting backoff in milliseconds (e.g. `500`)
* **Retry Backoff Max** - maximum backoff cap in milliseconds (e.g. `5000`)
```bash theme={null}
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"max_retries": 3,
"retry_backoff_initial": 500,
"retry_backoff_max": 5000
}
}'
```
```go theme={null}
func (a *MyAccount) GetConfigForProvider(provider schemas.ModelProvider) (*schemas.ProviderConfig, error) {
switch provider {
case schemas.OpenAI:
return &schemas.ProviderConfig{
NetworkConfig: schemas.NetworkConfig{
MaxRetries: 3,
RetryBackoffInitial: 500 * time.Millisecond,
RetryBackoffMax: 5 * time.Second,
},
ConcurrencyAndBufferSize: schemas.DefaultConcurrencyAndBufferSize,
}, nil
}
return nil, fmt.Errorf("provider %s not supported", provider)
}
```
```json theme={null}
{
"providers": {
"openai": {
"keys": [
{ "name": "openai-key-1", "value": "env.OPENAI_KEY_1", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-2", "value": "env.OPENAI_KEY_2", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-3", "value": "env.OPENAI_KEY_3", "models": ["*"], "weight": 1.0 }
],
"network_config": {
"max_retries": 3,
"retry_backoff_initial": 500,
"retry_backoff_max": 5000
}
}
}
}
```
| Field | Type | Default | Description |
| ----------------------- | ------------ | ------- | ----------------------------------------------------- |
| `max_retries` | integer | `0` | Number of additional attempts after the first failure |
| `retry_backoff_initial` | integer (ms) | `500` | Starting backoff duration in milliseconds |
| `retry_backoff_max` | integer (ms) | `5000` | Maximum backoff cap in milliseconds |
### Key rotation on per-key failures
Key rotation on retries requires **v1.5.0-prerelease4 or later**. Rotation on auth (401/403) and billing (402) errors (in addition to rate limits) requires the retry-logic-enhancements release.
When you configure multiple API keys for a provider, Bifrost automatically rotates to a fresh key when the failure is bound to the credential rather than the request:
* **`429 Too Many Requests`** — this key is rate-limited; another may have spare quota.
* **`401 Unauthorized` / `403 Forbidden`** — bad / revoked key, or key lacks permission.
* **`402 Payment Required`** — billing issue on this key's account.
```json theme={null}
{
"providers": {
"openai": {
"keys": [
{ "name": "openai-key-1", "value": "env.OPENAI_KEY_1", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-2", "value": "env.OPENAI_KEY_2", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-3", "value": "env.OPENAI_KEY_3", "models": ["*"], "weight": 1.0 }
],
"network_config": {
"max_retries": 5
}
}
}
}
```
**Rate-limited keys** are tracked in a per-request `used` set. Once all keys in the pool have been tried, Bifrost resets that set and starts a fresh weighted round — a previously rate-limited key may have free quota by then. With 3 keys and `max_retries: 5`, Bifrost can cycle through all three keys twice before giving up.
**Auth and billing failures** (401/402/403) are different: the failing key is marked **permanently dead** for the remainder of the request and is never reset. A bad credential won't become valid by waiting. If every configured key ends up permanently dead, Bifrost returns `502 upstream_credentials_exhausted` and skips any remaining retries.
Key rotation on retries only applies when `max_retries > 0` and more than one key is configured for the provider. With a single key, all retries reuse that key (and a permanent per-key failure terminates immediately with `502`).
***
## Fallbacks
Fallbacks provide automatic failover to a different provider when the primary fails after exhausting all its retries. Each fallback is tried in order until one succeeds.
### How fallbacks work
1. **Primary attempt**: Tries your configured provider with its full retry budget
2. **Fallback decision**: If the primary fails (and the error is retryable at the provider level), Bifrost moves to the first fallback
3. **Sequential fallbacks**: Each fallback provider also gets its own full retry budget
4. **First success wins**: Returns the response from the first provider that succeeds
5. **All fail**: Returns the original error from the primary provider. Exception: if a plugin on a fallback provider sets `AllowFallbacks = false` on the error (e.g. a security or compliance plugin that should halt the chain regardless of remaining fallbacks), Bifrost stops immediately and returns that fallback's error rather than continuing to the next provider or returning the primary error.
Each fallback is treated as a completely fresh request - all configured plugins (semantic caching, governance, logging) run again for the fallback provider.
### Implementation
Pass a `fallbacks` array in the request body. Each entry specifies a `provider/model` string:
```bash theme={null}
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "Explain quantum computing in simple terms"
}
],
"fallbacks": [
"anthropic/claude-3-5-sonnet-20241022",
"bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
],
"max_tokens": 1000,
"temperature": 0.7
}'
```
The response `extra_fields.provider` tells you which provider actually served the request:
```json theme={null}
{
"id": "chatcmpl-123",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Quantum computing is like having a super-powered calculator..."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 12,
"completion_tokens": 150,
"total_tokens": 162
},
"extra_fields": {
"provider": "anthropic",
"latency": 1.2
}
}
```
```go theme={null}
package main
import (
"context"
"fmt"
"github.com/maximhq/bifrost"
"github.com/maximhq/bifrost/core/schemas"
)
func chatWithFallbacks(client *bifrost.Bifrost) {
ctx := context.Background()
response, err := client.ChatCompletionRequest(
schemas.NewBifrostContext(ctx, schemas.NoDeadline),
&schemas.BifrostChatRequest{
Provider: schemas.OpenAI,
Model: "gpt-4o-mini",
Input: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleUser,
Content: &schemas.ChatMessageContent{
ContentStr: bifrost.Ptr("Explain quantum computing in simple terms"),
},
},
},
// Fallback chain: OpenAI → Anthropic → Bedrock
Fallbacks: []schemas.Fallback{
{Provider: schemas.Anthropic, Model: "claude-3-5-sonnet-20241022"},
{Provider: schemas.Bedrock, Model: "anthropic.claude-3-sonnet-20240229-v1:0"},
},
Params: &schemas.ChatParameters{
MaxCompletionTokens: bifrost.Ptr(1000),
Temperature: bifrost.Ptr(0.7),
},
},
)
if err != nil {
fmt.Printf("All providers failed: %v\n", err)
return
}
fmt.Printf("Response from %s: %s\n",
response.ExtraFields.Provider,
*response.Choices[0].BifrostNonStreamResponseChoice.Message.Content.ContentStr)
}
```
***
## How retries and fallbacks work together
The two mechanisms form a nested resilience loop. Retries run inside each provider attempt; fallbacks run across providers once retries are exhausted.
```mermaid theme={null}
sequenceDiagram
participant App
participant Bifrost
participant Primary as Primary Provider
participant FB1 as Fallback 1
participant FB2 as Fallback 2
App->>Bifrost: Request (primary + fallbacks)
rect rgb(220, 235, 250)
note over Bifrost,Primary: Primary provider attempt (with retries)
Bifrost->>Primary: Attempt 1
Primary-->>Bifrost: 401 Unauthorized
note over Bifrost: Key marked dead, rotate (no backoff)
Bifrost->>Primary: Attempt 2 (different key)
Primary-->>Bifrost: 429 Rate Limit
note over Bifrost: Backoff + rotate key
Bifrost->>Primary: Attempt 3 (different key)
Primary-->>Bifrost: 503 Unavailable
note over Bifrost: Backoff (same key)
Bifrost->>Primary: Attempt 4
Primary-->>Bifrost: 503 Unavailable
note over Bifrost: max_retries exhausted
end
rect rgb(235, 250, 220)
note over Bifrost,FB1: Fallback 1 attempt (with its own retries)
Bifrost->>FB1: Attempt 1
FB1-->>Bifrost: 500 Server Error
note over Bifrost: Backoff
Bifrost->>FB1: Attempt 2
FB1-->>Bifrost: ✓ Success
end
Bifrost-->>App: Response (from Fallback 1)
```
**Key point:** each provider in the chain - primary and every fallback - gets its own full `max_retries` budget. A primary configured with `max_retries: 3` and two fallbacks each also configured with `max_retries: 3` means up to 12 total attempts before giving up.
The retry budget is set per-provider in `network_config`. If your fallback providers have different retry configurations, each will use their own settings.
***
## Auditing retry and fallback decisions
Every retry transition and every fallback transition is recorded on the request's **routing engine log trail** under the engine name `core`. This is the same per-request trail that plugins like `governance`, `loadbalancing`, `routing-rule`, and `model-catalog` write to when they make routing decisions — so the chain reads end-to-end: which engine picked the primary, what the primary failed with, what core retried with, and which fallback ultimately served the response.
Entries core emits:
| Phase | Level | Shape |
| -------------------------------------- | ----- | ----------------------------------------------------------------------------------------- |
| Primary failed, entering fallback loop | Info | `Primary
Navigate to **Providers**, select a provider, and open the **Network Config** section.
Set:
* **Max Retries** - number of additional attempts after the first failure (e.g. `3`)
* **Retry Backoff Initial** - starting backoff in milliseconds (e.g. `500`)
* **Retry Backoff Max** - maximum backoff cap in milliseconds (e.g. `5000`)
```bash theme={null}
curl --location 'http://localhost:8080/api/providers' \
--header 'Content-Type: application/json' \
--data '{
"provider": "openai",
"keys": [
{
"name": "openai-key-1",
"value": "env.OPENAI_API_KEY",
"models": ["*"],
"weight": 1.0
}
],
"network_config": {
"max_retries": 3,
"retry_backoff_initial": 500,
"retry_backoff_max": 5000
}
}'
```
```go theme={null}
func (a *MyAccount) GetConfigForProvider(provider schemas.ModelProvider) (*schemas.ProviderConfig, error) {
switch provider {
case schemas.OpenAI:
return &schemas.ProviderConfig{
NetworkConfig: schemas.NetworkConfig{
MaxRetries: 3,
RetryBackoffInitial: 500 * time.Millisecond,
RetryBackoffMax: 5 * time.Second,
},
ConcurrencyAndBufferSize: schemas.DefaultConcurrencyAndBufferSize,
}, nil
}
return nil, fmt.Errorf("provider %s not supported", provider)
}
```
```json theme={null}
{
"providers": {
"openai": {
"keys": [
{ "name": "openai-key-1", "value": "env.OPENAI_KEY_1", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-2", "value": "env.OPENAI_KEY_2", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-3", "value": "env.OPENAI_KEY_3", "models": ["*"], "weight": 1.0 }
],
"network_config": {
"max_retries": 3,
"retry_backoff_initial": 500,
"retry_backoff_max": 5000
}
}
}
}
```
| Field | Type | Default | Description |
| ----------------------- | ------------ | ------- | ----------------------------------------------------- |
| `max_retries` | integer | `0` | Number of additional attempts after the first failure |
| `retry_backoff_initial` | integer (ms) | `500` | Starting backoff duration in milliseconds |
| `retry_backoff_max` | integer (ms) | `5000` | Maximum backoff cap in milliseconds |
### Key rotation on per-key failures
Key rotation on retries requires **v1.5.0-prerelease4 or later**. Rotation on auth (401/403) and billing (402) errors (in addition to rate limits) requires the retry-logic-enhancements release.
When you configure multiple API keys for a provider, Bifrost automatically rotates to a fresh key when the failure is bound to the credential rather than the request:
* **`429 Too Many Requests`** — this key is rate-limited; another may have spare quota.
* **`401 Unauthorized` / `403 Forbidden`** — bad / revoked key, or key lacks permission.
* **`402 Payment Required`** — billing issue on this key's account.
```json theme={null}
{
"providers": {
"openai": {
"keys": [
{ "name": "openai-key-1", "value": "env.OPENAI_KEY_1", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-2", "value": "env.OPENAI_KEY_2", "models": ["*"], "weight": 1.0 },
{ "name": "openai-key-3", "value": "env.OPENAI_KEY_3", "models": ["*"], "weight": 1.0 }
],
"network_config": {
"max_retries": 5
}
}
}
}
```
**Rate-limited keys** are tracked in a per-request `used` set. Once all keys in the pool have been tried, Bifrost resets that set and starts a fresh weighted round — a previously rate-limited key may have free quota by then. With 3 keys and `max_retries: 5`, Bifrost can cycle through all three keys twice before giving up.
**Auth and billing failures** (401/402/403) are different: the failing key is marked **permanently dead** for the remainder of the request and is never reset. A bad credential won't become valid by waiting. If every configured key ends up permanently dead, Bifrost returns `502 upstream_credentials_exhausted` and skips any remaining retries.
Key rotation on retries only applies when `max_retries > 0` and more than one key is configured for the provider. With a single key, all retries reuse that key (and a permanent per-key failure terminates immediately with `502`).
***
## Fallbacks
Fallbacks provide automatic failover to a different provider when the primary fails after exhausting all its retries. Each fallback is tried in order until one succeeds.
### How fallbacks work
1. **Primary attempt**: Tries your configured provider with its full retry budget
2. **Fallback decision**: If the primary fails (and the error is retryable at the provider level), Bifrost moves to the first fallback
3. **Sequential fallbacks**: Each fallback provider also gets its own full retry budget
4. **First success wins**: Returns the response from the first provider that succeeds
5. **All fail**: Returns the original error from the primary provider. Exception: if a plugin on a fallback provider sets `AllowFallbacks = false` on the error (e.g. a security or compliance plugin that should halt the chain regardless of remaining fallbacks), Bifrost stops immediately and returns that fallback's error rather than continuing to the next provider or returning the primary error.
Each fallback is treated as a completely fresh request - all configured plugins (semantic caching, governance, logging) run again for the fallback provider.
### Implementation
Pass a `fallbacks` array in the request body. Each entry specifies a `provider/model` string:
```bash theme={null}
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "Explain quantum computing in simple terms"
}
],
"fallbacks": [
"anthropic/claude-3-5-sonnet-20241022",
"bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
],
"max_tokens": 1000,
"temperature": 0.7
}'
```
The response `extra_fields.provider` tells you which provider actually served the request:
```json theme={null}
{
"id": "chatcmpl-123",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Quantum computing is like having a super-powered calculator..."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 12,
"completion_tokens": 150,
"total_tokens": 162
},
"extra_fields": {
"provider": "anthropic",
"latency": 1.2
}
}
```
```go theme={null}
package main
import (
"context"
"fmt"
"github.com/maximhq/bifrost"
"github.com/maximhq/bifrost/core/schemas"
)
func chatWithFallbacks(client *bifrost.Bifrost) {
ctx := context.Background()
response, err := client.ChatCompletionRequest(
schemas.NewBifrostContext(ctx, schemas.NoDeadline),
&schemas.BifrostChatRequest{
Provider: schemas.OpenAI,
Model: "gpt-4o-mini",
Input: []schemas.ChatMessage{
{
Role: schemas.ChatMessageRoleUser,
Content: &schemas.ChatMessageContent{
ContentStr: bifrost.Ptr("Explain quantum computing in simple terms"),
},
},
},
// Fallback chain: OpenAI → Anthropic → Bedrock
Fallbacks: []schemas.Fallback{
{Provider: schemas.Anthropic, Model: "claude-3-5-sonnet-20241022"},
{Provider: schemas.Bedrock, Model: "anthropic.claude-3-sonnet-20240229-v1:0"},
},
Params: &schemas.ChatParameters{
MaxCompletionTokens: bifrost.Ptr(1000),
Temperature: bifrost.Ptr(0.7),
},
},
)
if err != nil {
fmt.Printf("All providers failed: %v\n", err)
return
}
fmt.Printf("Response from %s: %s\n",
response.ExtraFields.Provider,
*response.Choices[0].BifrostNonStreamResponseChoice.Message.Content.ContentStr)
}
```
***
## How retries and fallbacks work together
The two mechanisms form a nested resilience loop. Retries run inside each provider attempt; fallbacks run across providers once retries are exhausted.
```mermaid theme={null}
sequenceDiagram
participant App
participant Bifrost
participant Primary as Primary Provider
participant FB1 as Fallback 1
participant FB2 as Fallback 2
App->>Bifrost: Request (primary + fallbacks)
rect rgb(220, 235, 250)
note over Bifrost,Primary: Primary provider attempt (with retries)
Bifrost->>Primary: Attempt 1
Primary-->>Bifrost: 401 Unauthorized
note over Bifrost: Key marked dead, rotate (no backoff)
Bifrost->>Primary: Attempt 2 (different key)
Primary-->>Bifrost: 429 Rate Limit
note over Bifrost: Backoff + rotate key
Bifrost->>Primary: Attempt 3 (different key)
Primary-->>Bifrost: 503 Unavailable
note over Bifrost: Backoff (same key)
Bifrost->>Primary: Attempt 4
Primary-->>Bifrost: 503 Unavailable
note over Bifrost: max_retries exhausted
end
rect rgb(235, 250, 220)
note over Bifrost,FB1: Fallback 1 attempt (with its own retries)
Bifrost->>FB1: Attempt 1
FB1-->>Bifrost: 500 Server Error
note over Bifrost: Backoff
Bifrost->>FB1: Attempt 2
FB1-->>Bifrost: ✓ Success
end
Bifrost-->>App: Response (from Fallback 1)
```
**Key point:** each provider in the chain - primary and every fallback - gets its own full `max_retries` budget. A primary configured with `max_retries: 3` and two fallbacks each also configured with `max_retries: 3` means up to 12 total attempts before giving up.
The retry budget is set per-provider in `network_config`. If your fallback providers have different retry configurations, each will use their own settings.
***
## Auditing retry and fallback decisions
Every retry transition and every fallback transition is recorded on the request's **routing engine log trail** under the engine name `core`. This is the same per-request trail that plugins like `governance`, `loadbalancing`, `routing-rule`, and `model-catalog` write to when they make routing decisions — so the chain reads end-to-end: which engine picked the primary, what the primary failed with, what core retried with, and which fallback ultimately served the response.
Entries core emits:
| Phase | Level | Shape |
| -------------------------------------- | ----- | ----------------------------------------------------------------------------------------- |
| Primary failed, entering fallback loop | Info | `Primary / failed ( HTTP ); evaluating N configured fallback(s)` |
| Each fallback iteration | Info | `Trying fallback i/N: / (previous attempt failed: HTTP )` |
| Fallback skipped (no provider config) | Warn | `Fallback / skipped: missing provider config` |
| Fallback succeeded | Info | `Request served by fallback / (attempt i/N)` |
| Fallback halted by short-circuit | Error | `Fallback / failed ( HTTP ); halting further fallbacks` |
| All fallbacks exhausted | Error | `All N fallback(s) exhausted; returning primary error ( HTTP )` |
| Retry transition (rotated key) | Info | `Retry n/N for / (previous attempt failed: HTTP ; rotated key=)` |
| Retry transition (same key) | Info | `Retry n/N for / (previous attempt failed: HTTP ; same key=)` |
| Retry transition (keyless provider) | Info | `Retry n/N for / (previous attempt failed: HTTP )` |
| Retries succeeded | Info | `Request to / succeeded after N retry attempt(s)` |
| Retries exhausted | Error | `Retries exhausted for / after N attempt(s); last error: HTTP ` |
The failure context attached to each entry is intentionally categorical — only the error type (e.g. `rate_limit_error`) and HTTP status code. The upstream provider message is *never* included, since providers can echo back API keys, tokens, or user input. The key identifier surfaced in retry rotation notes is the user-set key **name**, not the secret value.
When core emits at least one entry on a request, it also adds itself to the request log's `routing_engines_used` field (deduped — `core` appears at most once per request even if both the retry and fallback orchestrators were involved).
***
## Real-world scenarios
**Scenario 1: Rate limiting with key rotation**
OpenAI key 1 hits its rate limit. Bifrost rotates to key 2 on the next retry - no fallback needed, the request succeeds within the same provider.
**Scenario 2: Provider outage**
OpenAI is experiencing downtime (returning `503`). Bifrost retries with the same key (transient server issue), exhausts `max_retries`, then fails over to Anthropic. Anthropic succeeds on the first attempt.
**Scenario 3: Cascading failure**
Both primary and first fallback are down. Bifrost works through each provider's retry budget sequentially until the second fallback succeeds.
**Scenario 4: Cost-sensitive fallback**
Primary: a premium model for quality. Fallback: a cost-effective alternative. Governance rules can trigger a budget-exceeded error on the primary, which cascades into the fallback chain.
**Scenario 5: Revoked credential**
OpenAI key 1 was rotated out-of-band and now returns `401`. Bifrost marks key 1 permanently dead for this request and immediately rotates to key 2 (no backoff), which succeeds. Future requests will retry key 1 again — the dead-key set is per-request, not persistent. If every configured key was revoked, Bifrost would return `502 upstream_credentials_exhausted` instead of bubbling up the raw `401` (which would falsely suggest the *caller's* Bifrost API key is the problem).
***
## Plugin execution
When a fallback is triggered, the fallback request is treated as completely new:
* Semantic cache checks run again (the fallback provider may have a cached response)
* Governance rules apply to the new provider
* Logging captures the fallback attempt separately
* All configured plugins execute fresh for each provider in the chain
**Plugin fallback control:** Plugins can prevent fallbacks from being triggered for specific error types. For example, a security plugin might disable fallbacks for compliance reasons. When a plugin sets `AllowFallbacks = false` on the error, the fallback chain is skipped entirely and the original error is returned immediately.
***
## Next steps
* **[Keys Management](./keys-management)** - Configure multiple API keys per provider to enable key rotation on retries
* **[Governance](./governance/virtual-keys)** - Use virtual keys and routing rules to control which providers are used
* **[Observability](./observability/default)** - Track retry counts and fallback usage in your logs